第三章 内存管理
3.1 内存管理
3.1.0 前置知识
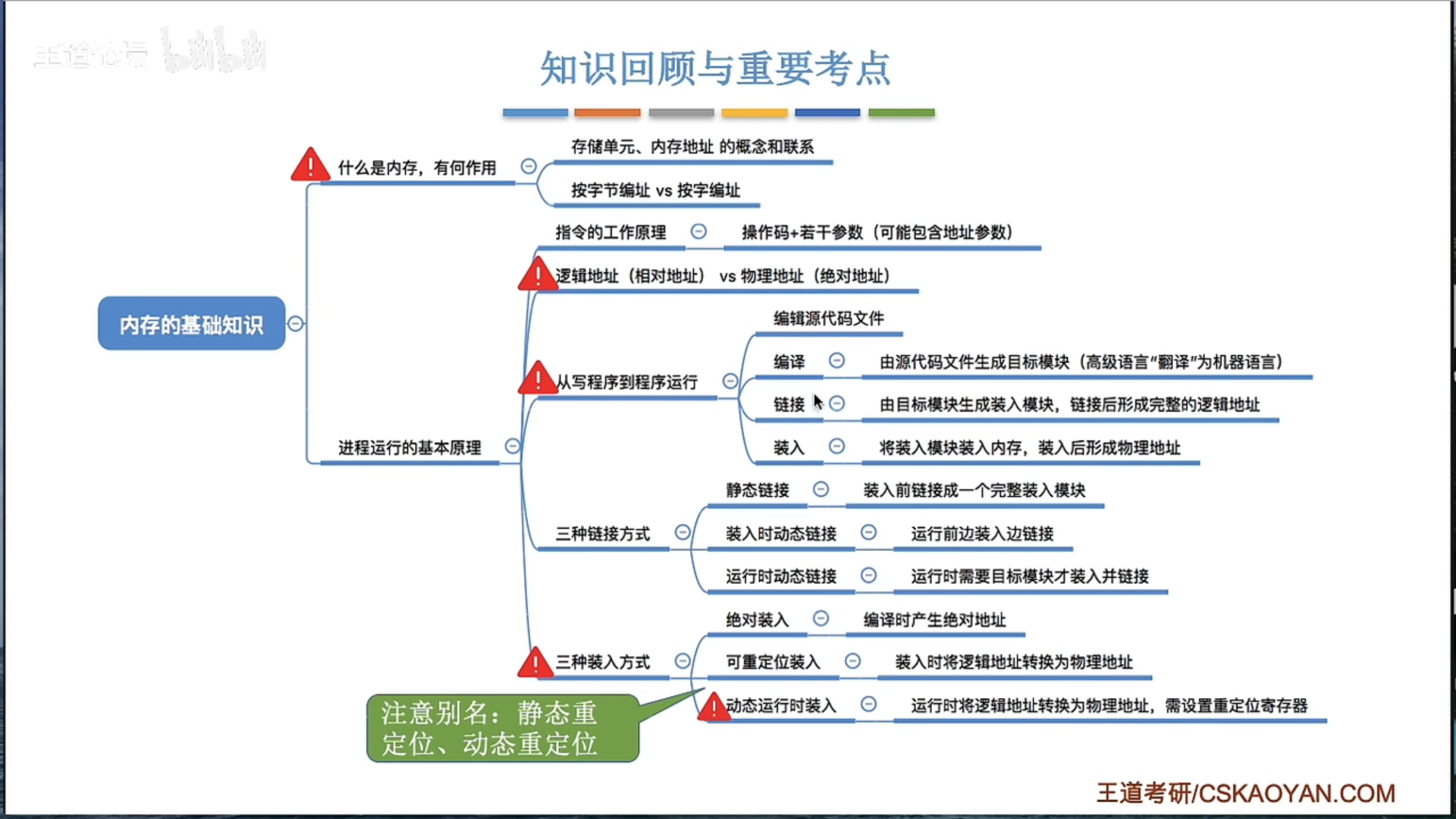

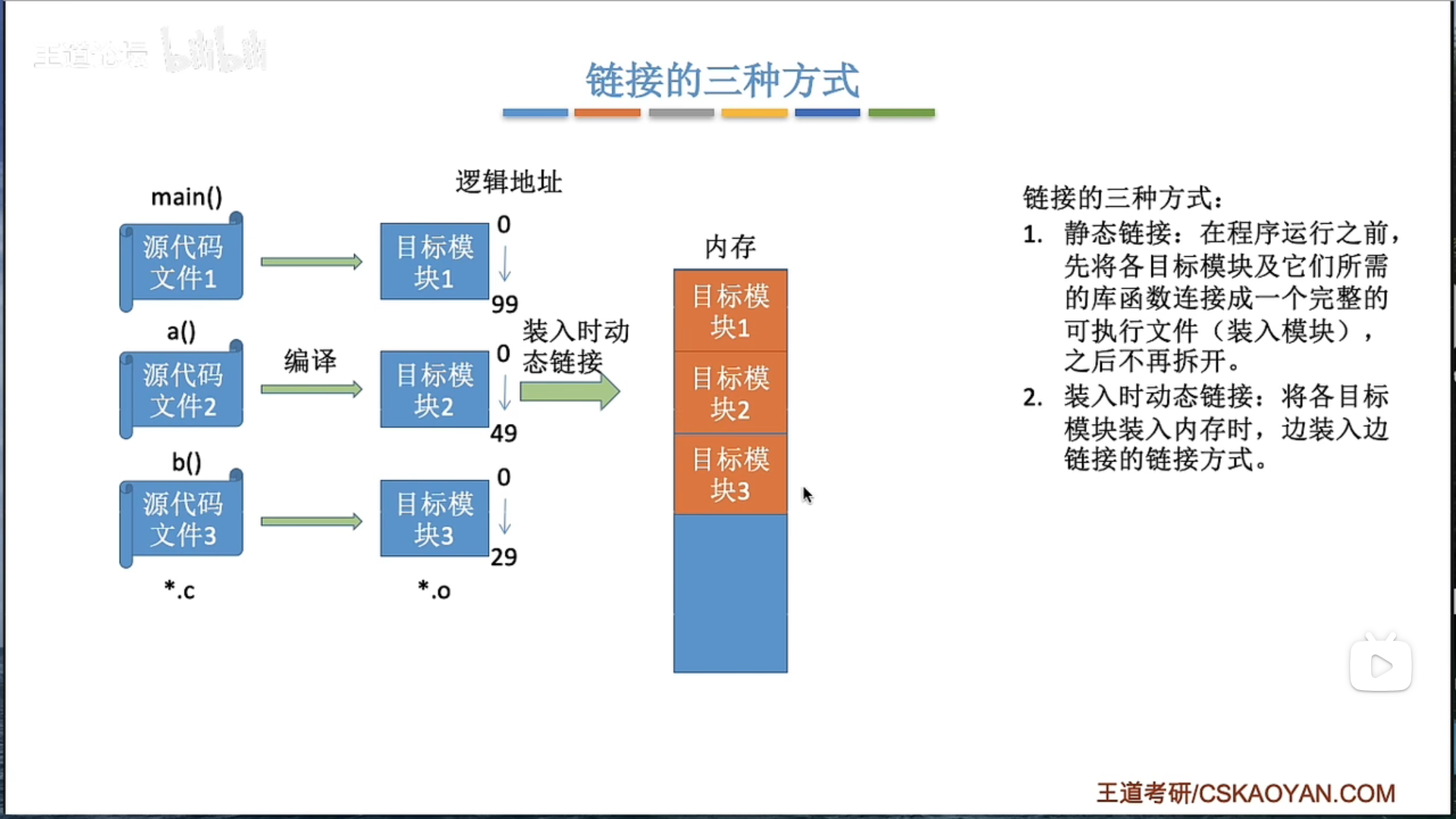
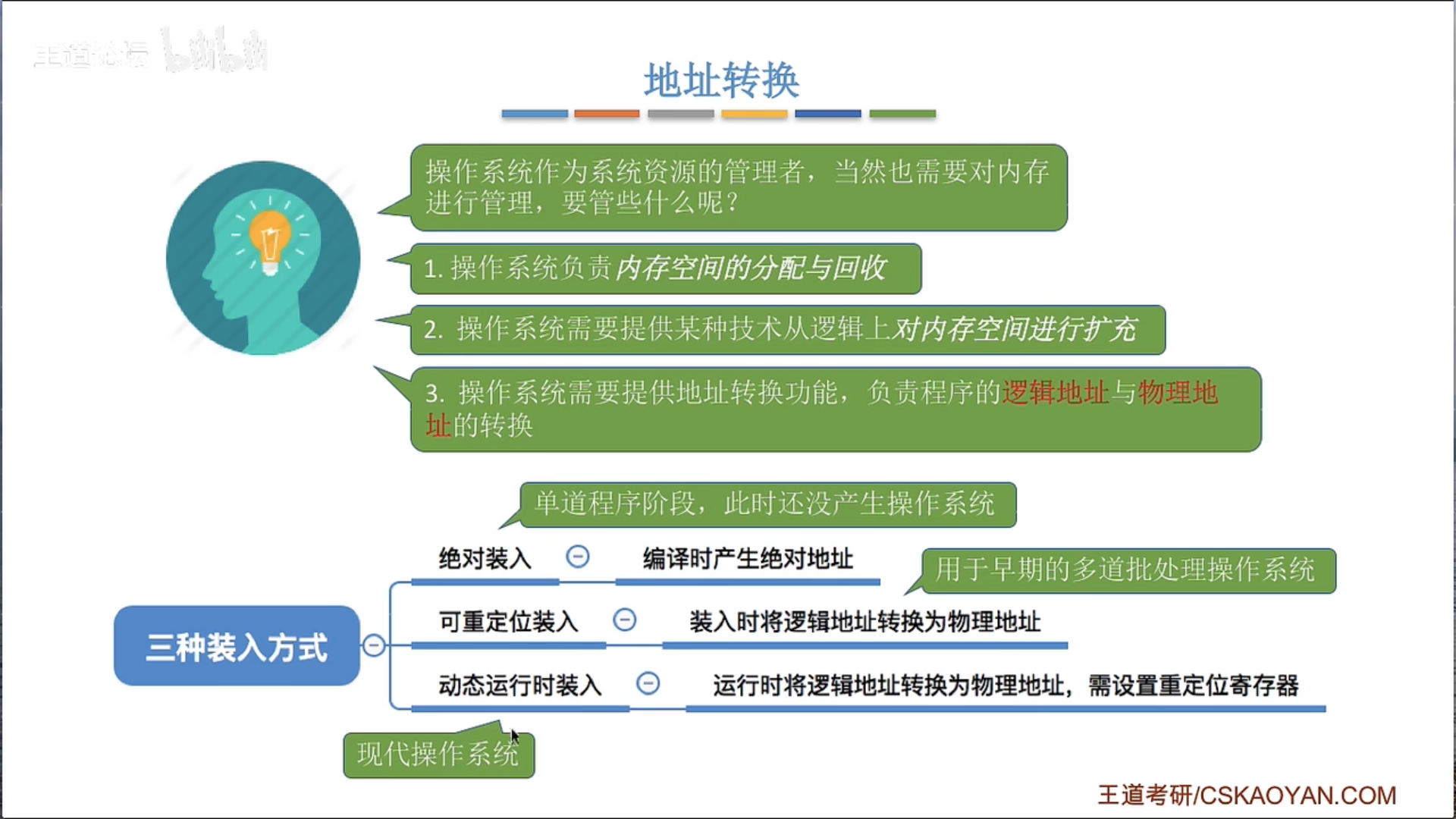
三种装入方式


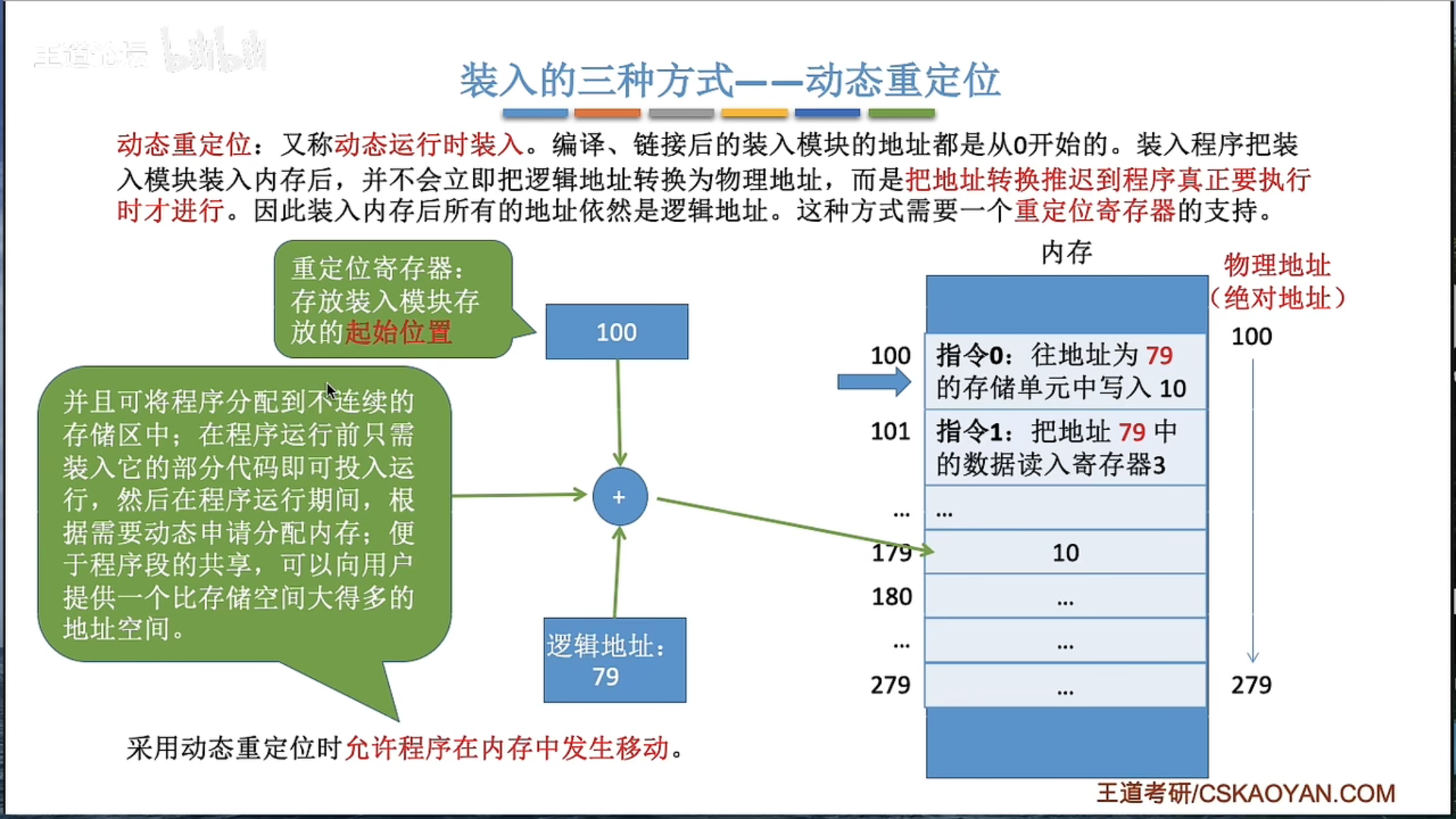
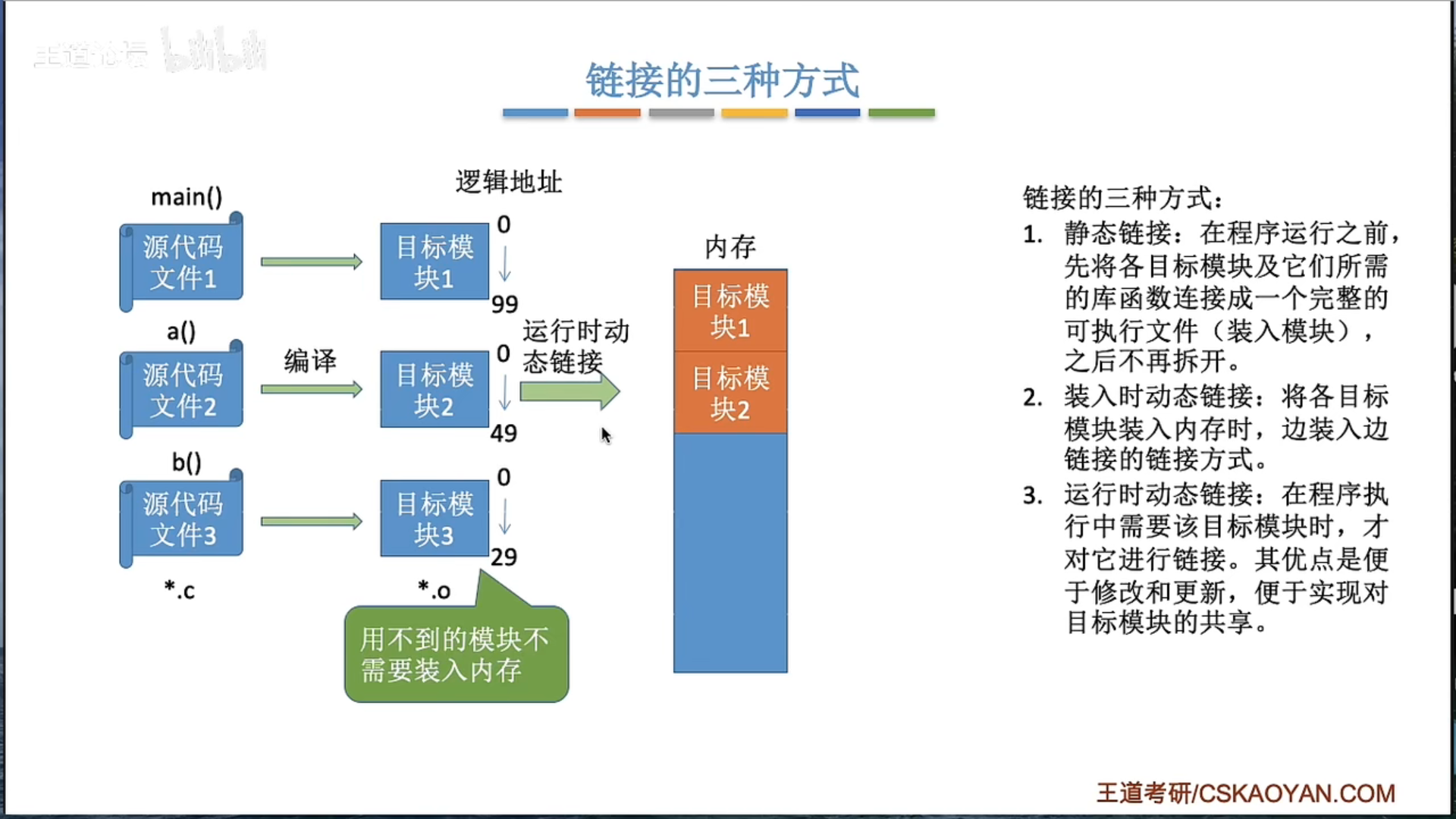
动态运行时装入便于程序段的共享吗?
是的,动态运行时装载确实有利于程序段的共享。
在现代操作系统中,动态运行时装载(或称为动态链接)是一种在程序执行期间,而不是在编译期间,将程序的各个模块组装到一起的方式。动态链接的主要优势之一就是共享代码。
当多个正在运行的程序同时使用同一动态链接库中的代码时,这段代码只需要在内存中存在一份即可,所有程序都可以共享这一份代码。这样,不仅可以减少内存使用量,而且还能减小程序的磁盘占用空间,因为这段代码只需要在磁盘上存在一份即可。
此外,动态链接还具有其他一些优点,如易于升级和维护(可以通过替换动态链接库来更新功能,而无需重新编译整个程序),以及能够支持插件和扩展功能等。
(笔者注:chatgpt的总结)
在计算机科学中,程序的装入方式主要有以下三种:
绝对装入(Absolute Loading):在这种方法中,程序在编译时确定其在内存中的位置。编译器将生成一个绝对地址的代码,然后装入程序将这些代码加载到内存的指定位置。这是最简单的装入方式,但是它要求程序在运行期间始终位于同一内存位置,这使得它无法满足现代多任务操作系统的需求。
可重定位装入(Relocatable Loading):在这种方法中,程序在编译时不确定其在内存中的位置。编译器将生成可重定位的代码,然后在装入程序时,链接器会根据当前内存的使用情况,选择一个适当的位置加载程序,并修改程序中的地址引用。这使得程序可以在运行时被加载到内存的任何位置。
动态运行时装入(Dynamic Run-time Loading):在这种方法中,程序在运行时才确定其在内存中的位置。程序的一部分(如主程序)首先被加载到内存,然后在运行时,当需要使用到其它部分(如库函数)时,才将其加载到内存。这种方式可以有效地管理内存,只加载实际需要的部分,同时也支持动态链接和共享代码。
这三种装入方式从绝对装入到动态运行时装入,其灵活性和复杂性逐渐增加。现代操作系统主要使用可重定位装入和动态运行时装入方式,以支持多任务和动态链接等功能。
三种链接方式
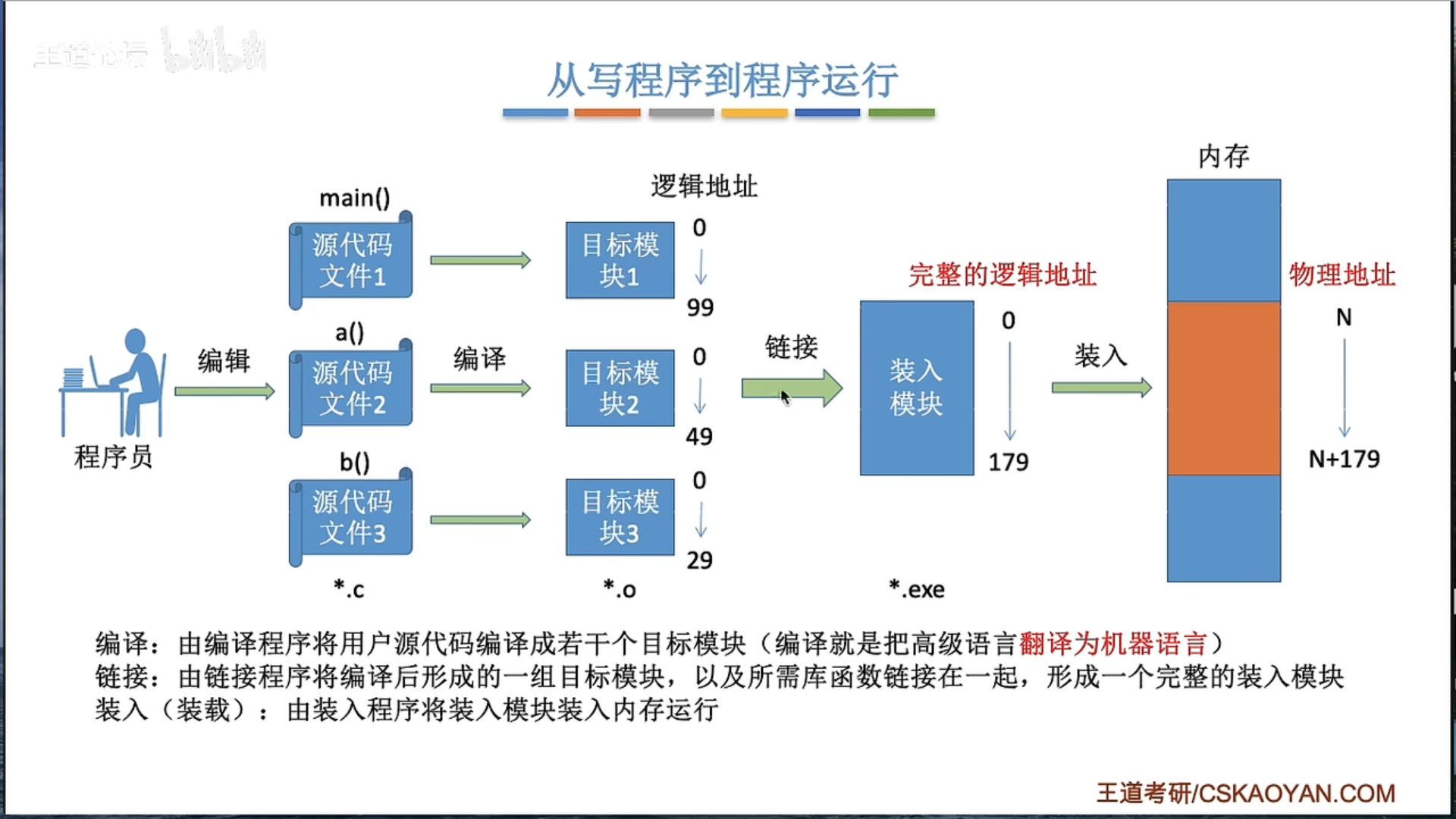
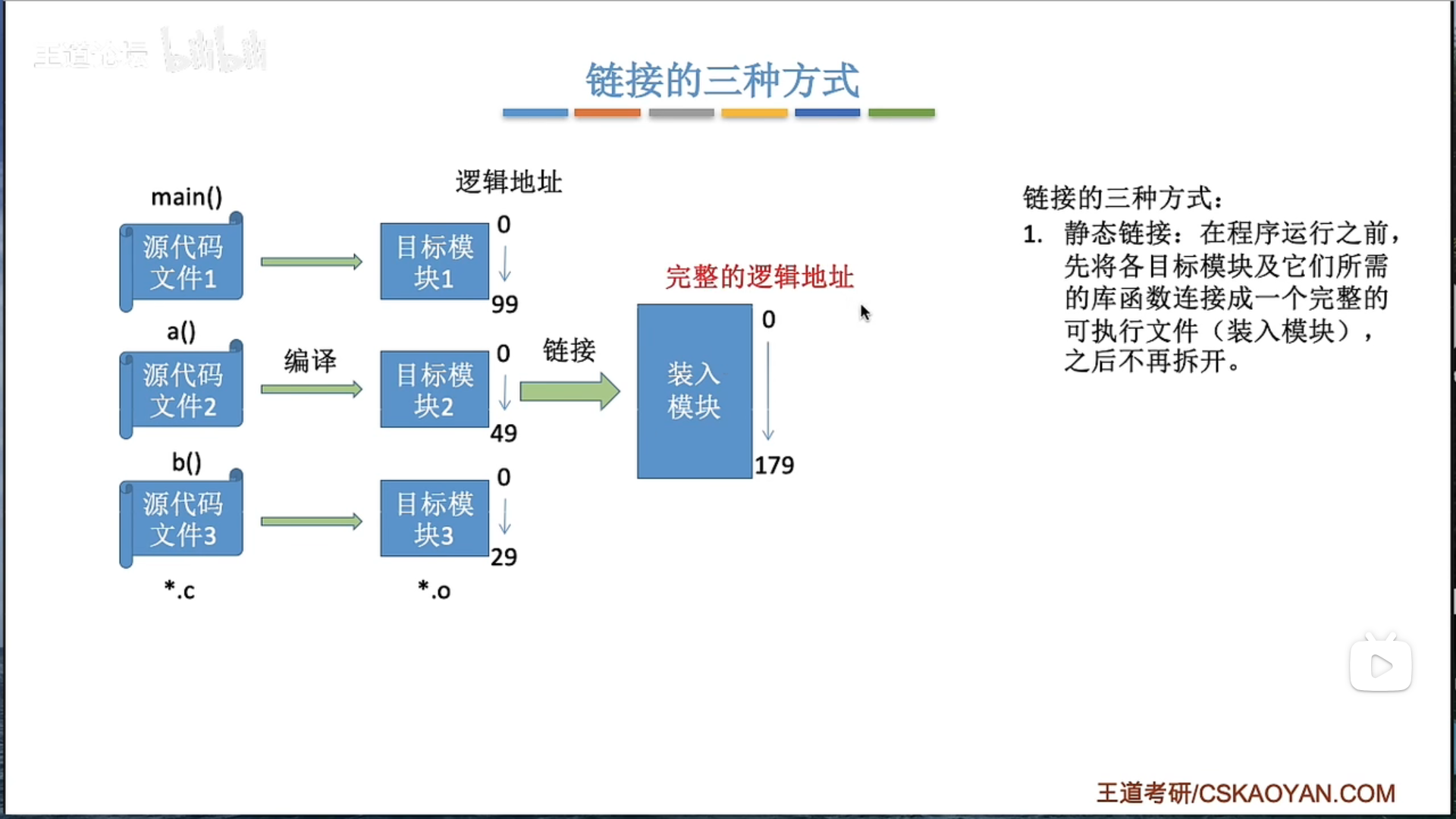
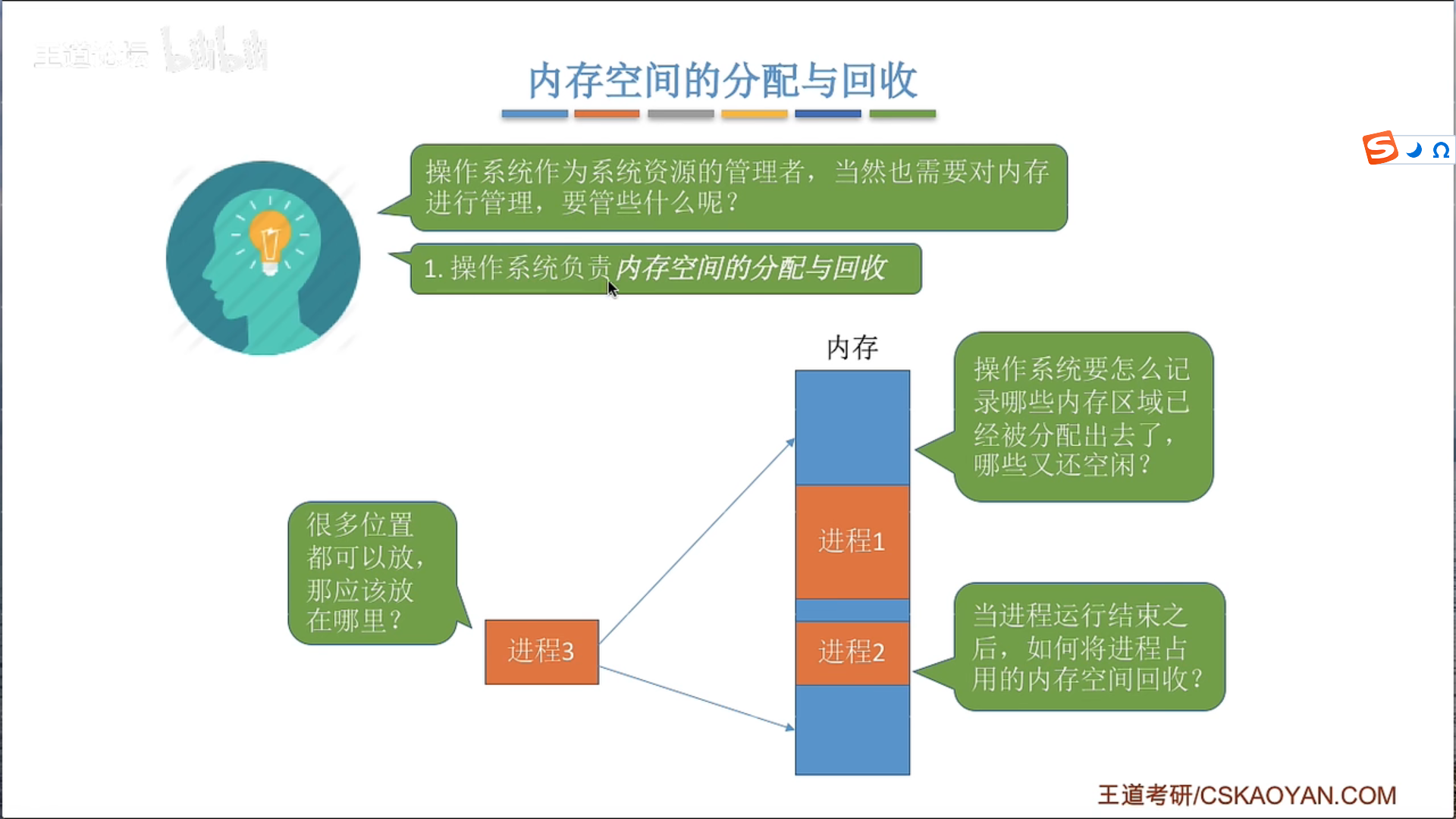
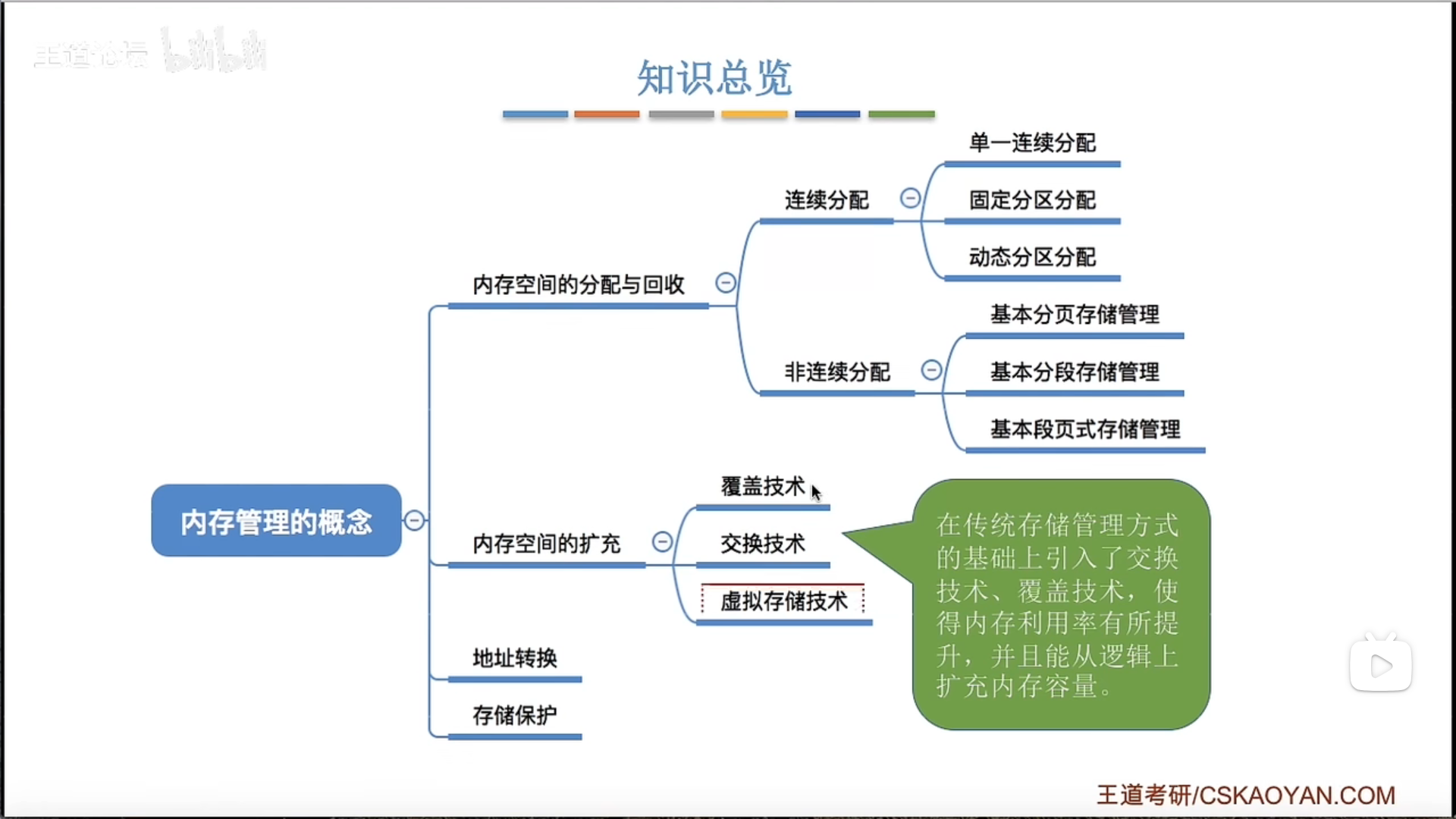
3.1.1 内存管理概念


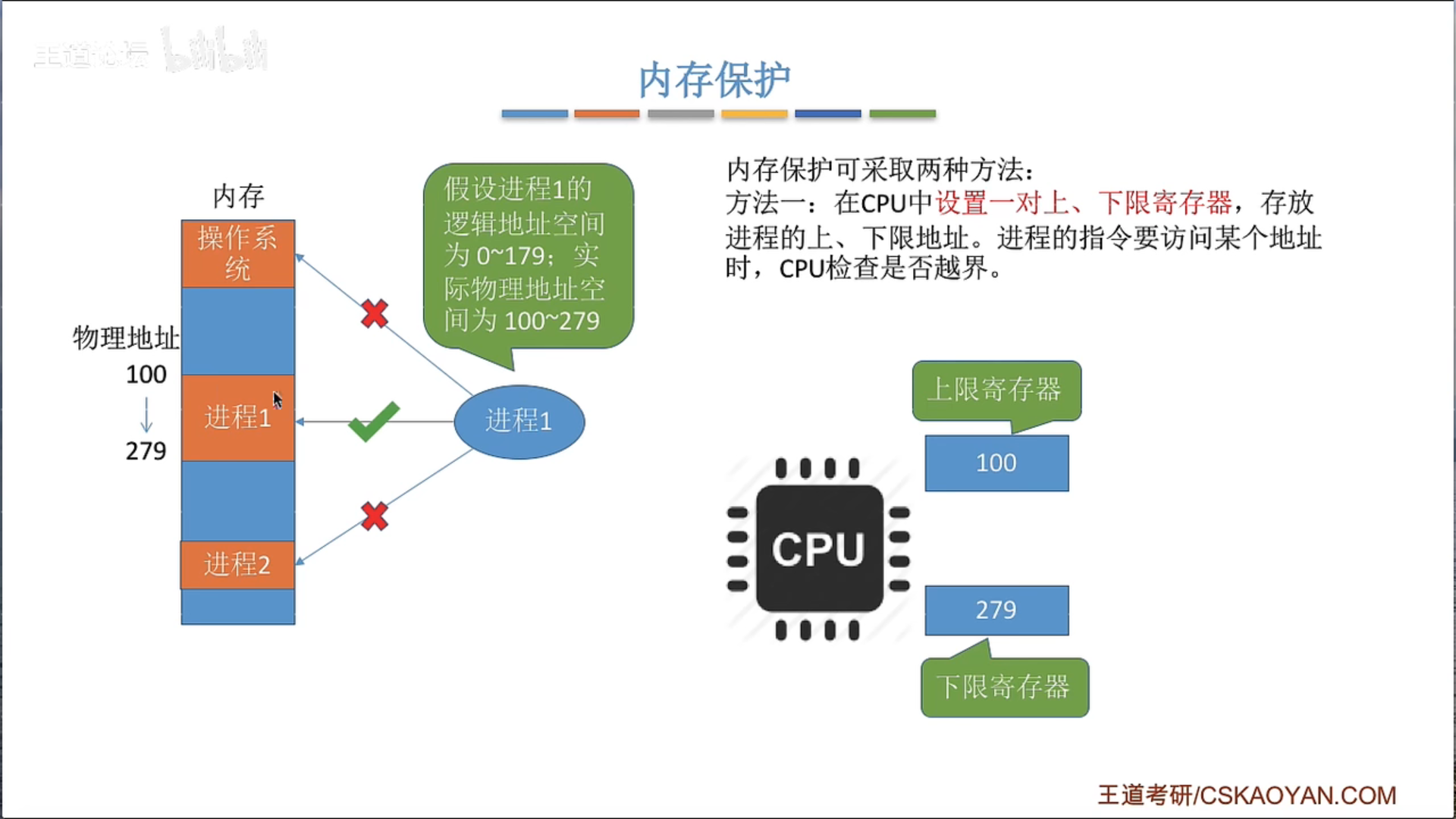
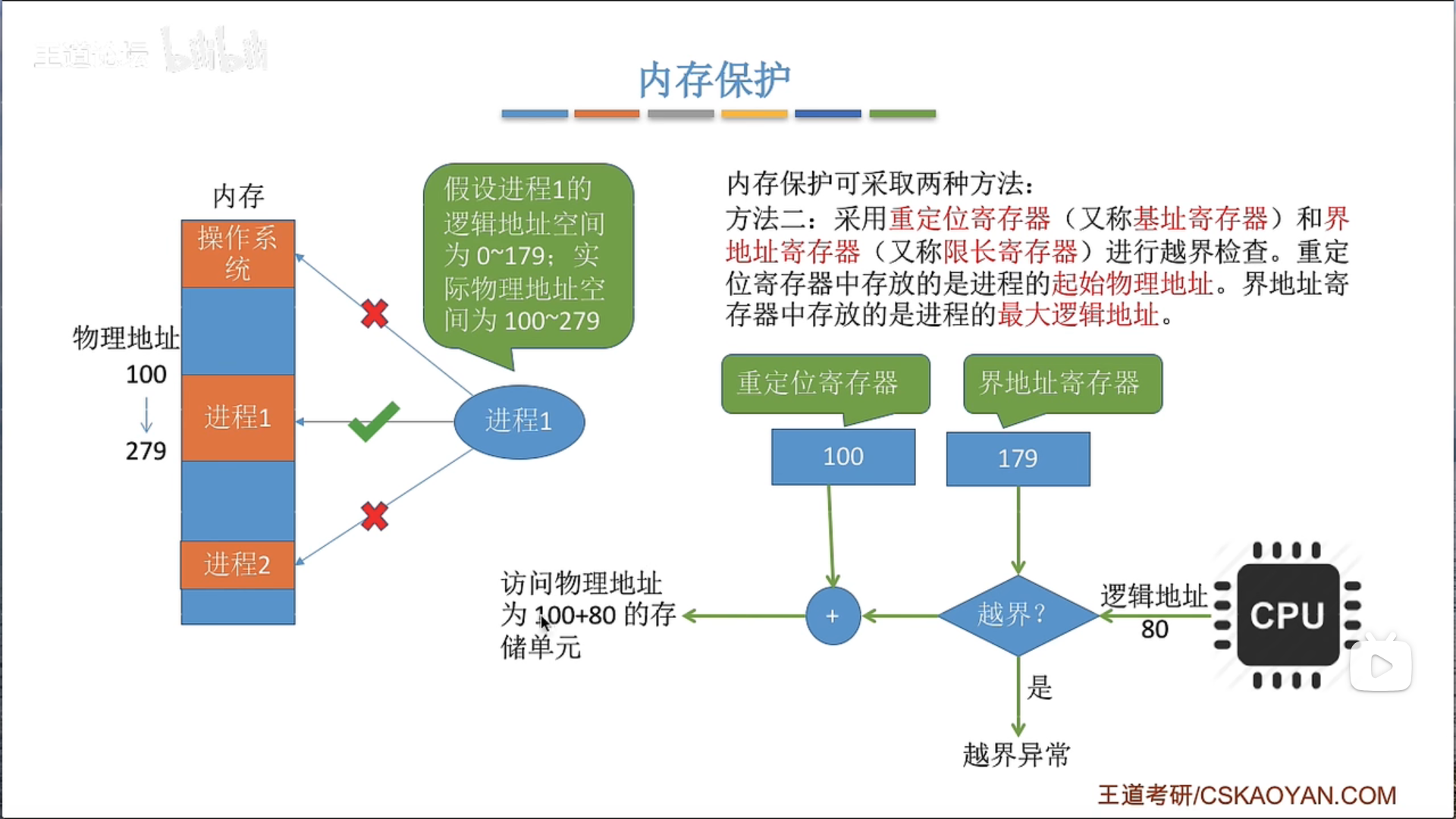
内存保护
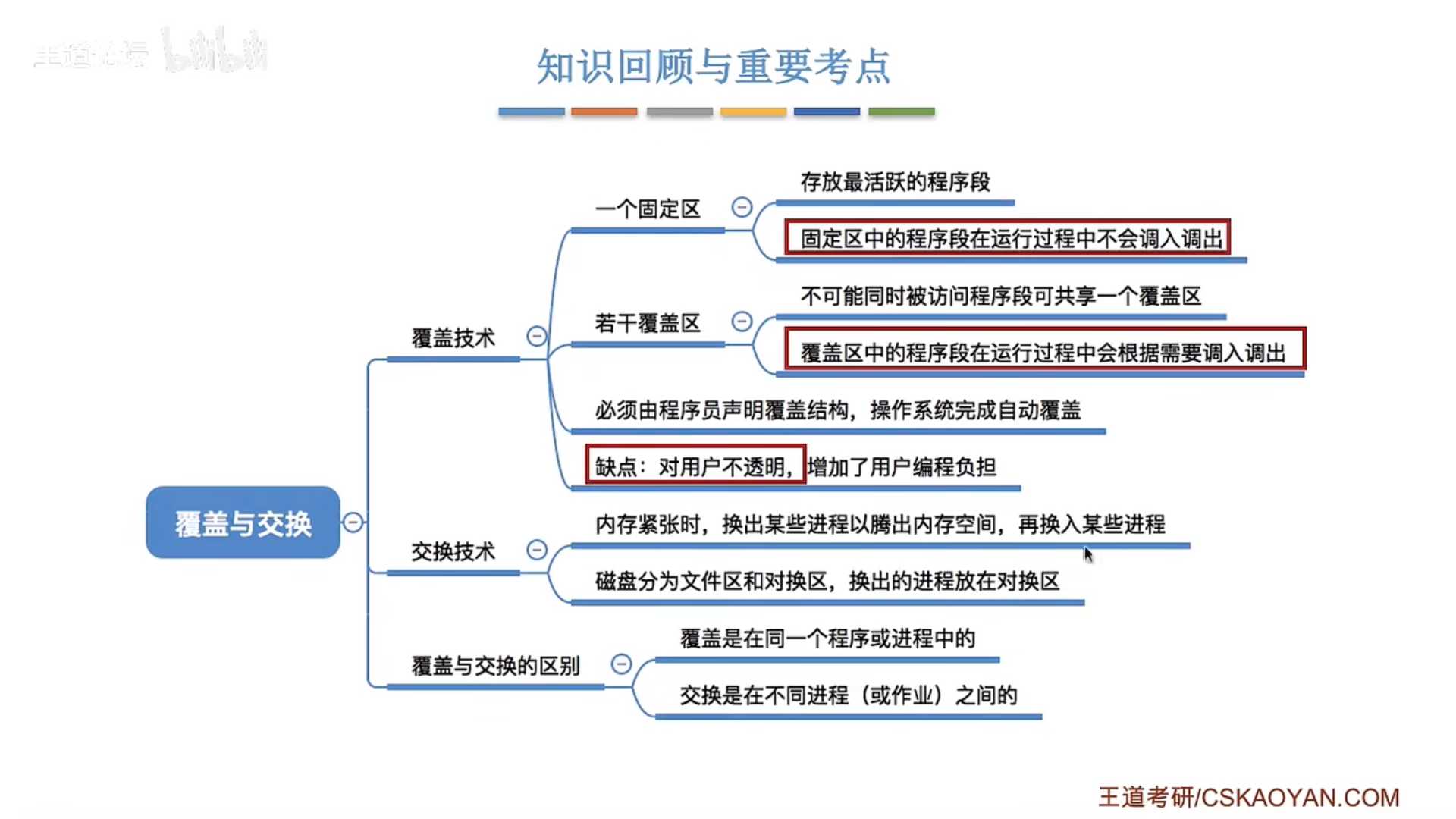
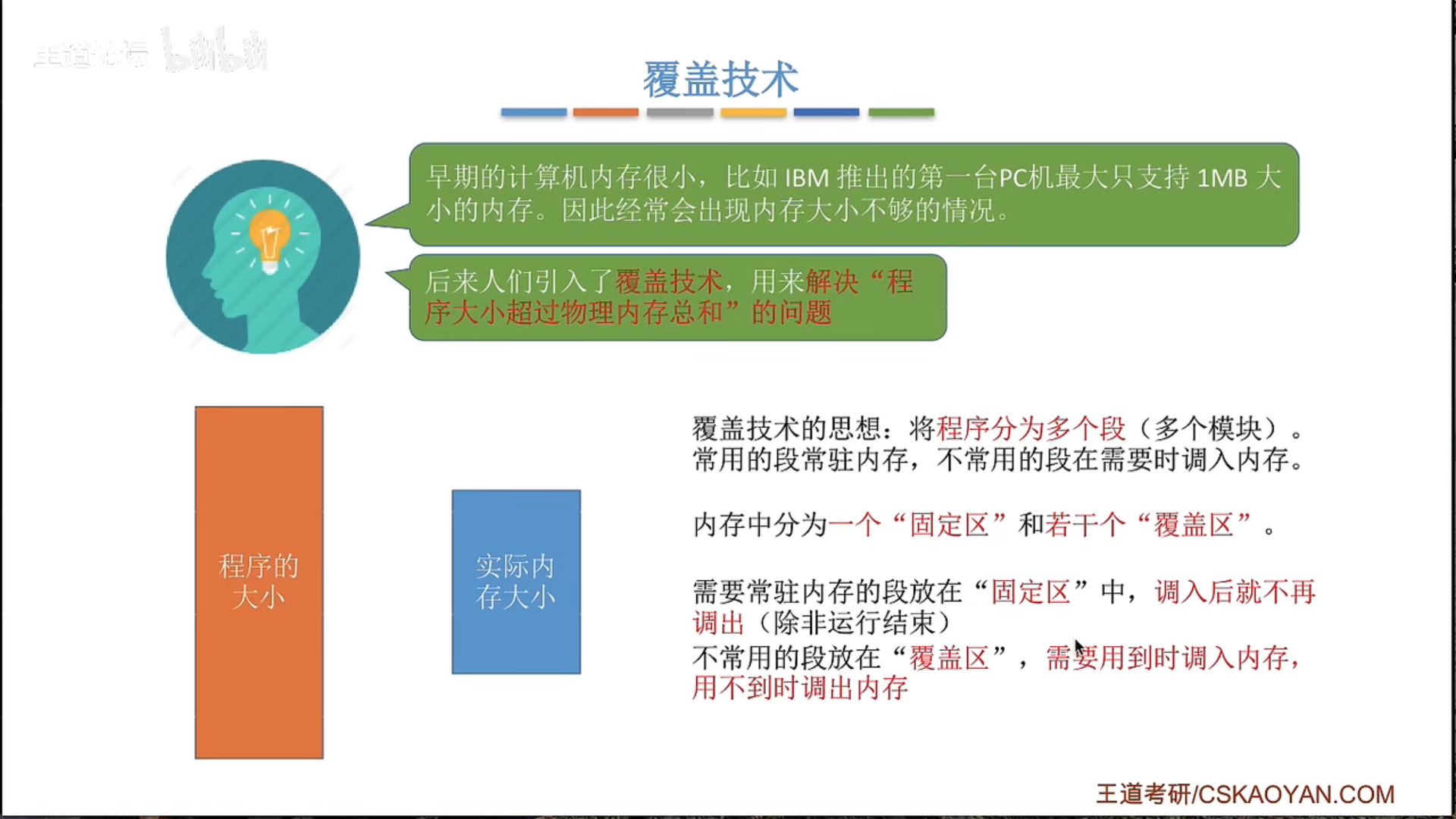
3.1.2 覆盖与交换*
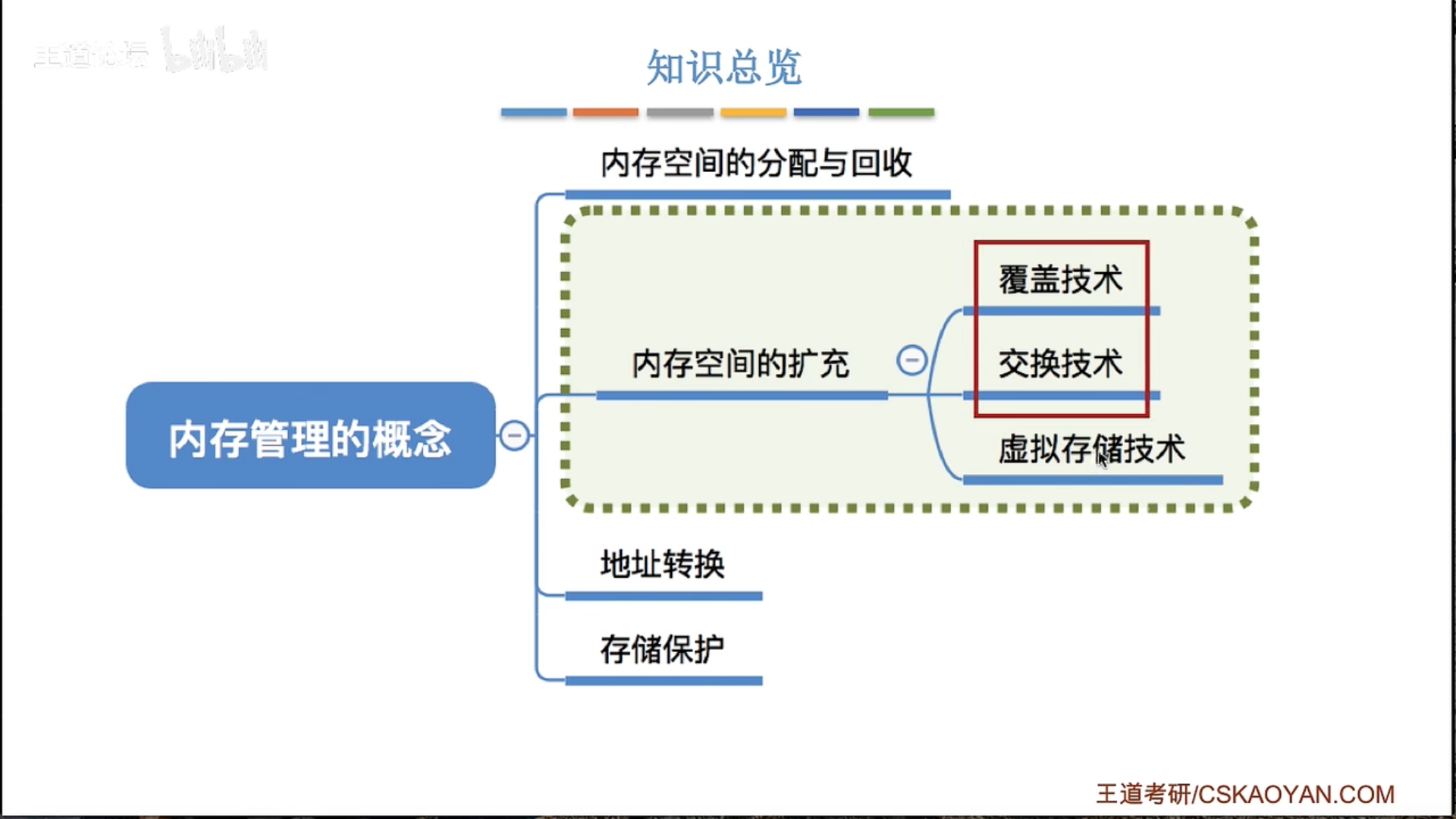




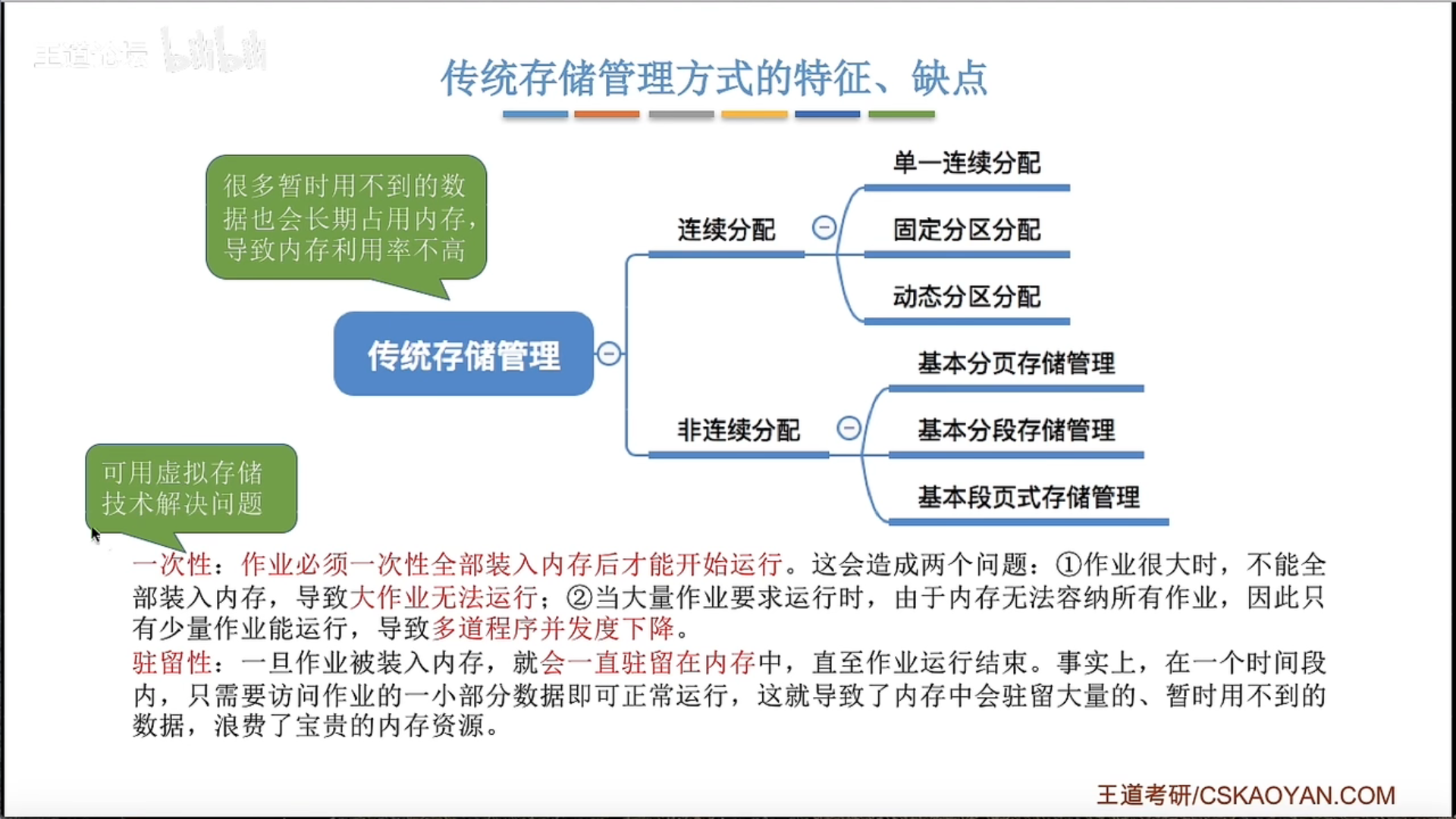
3.1.3 连续分配
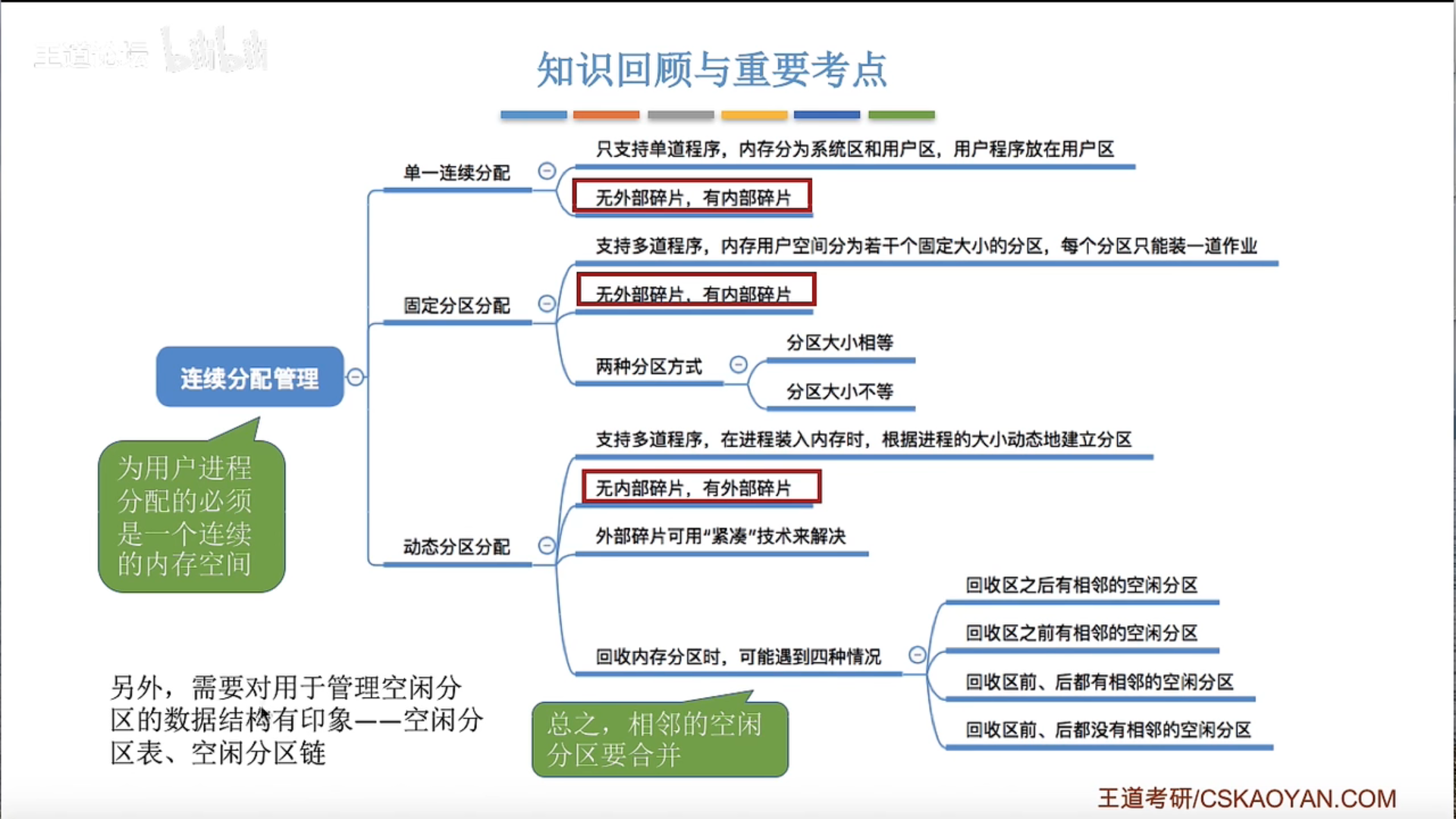
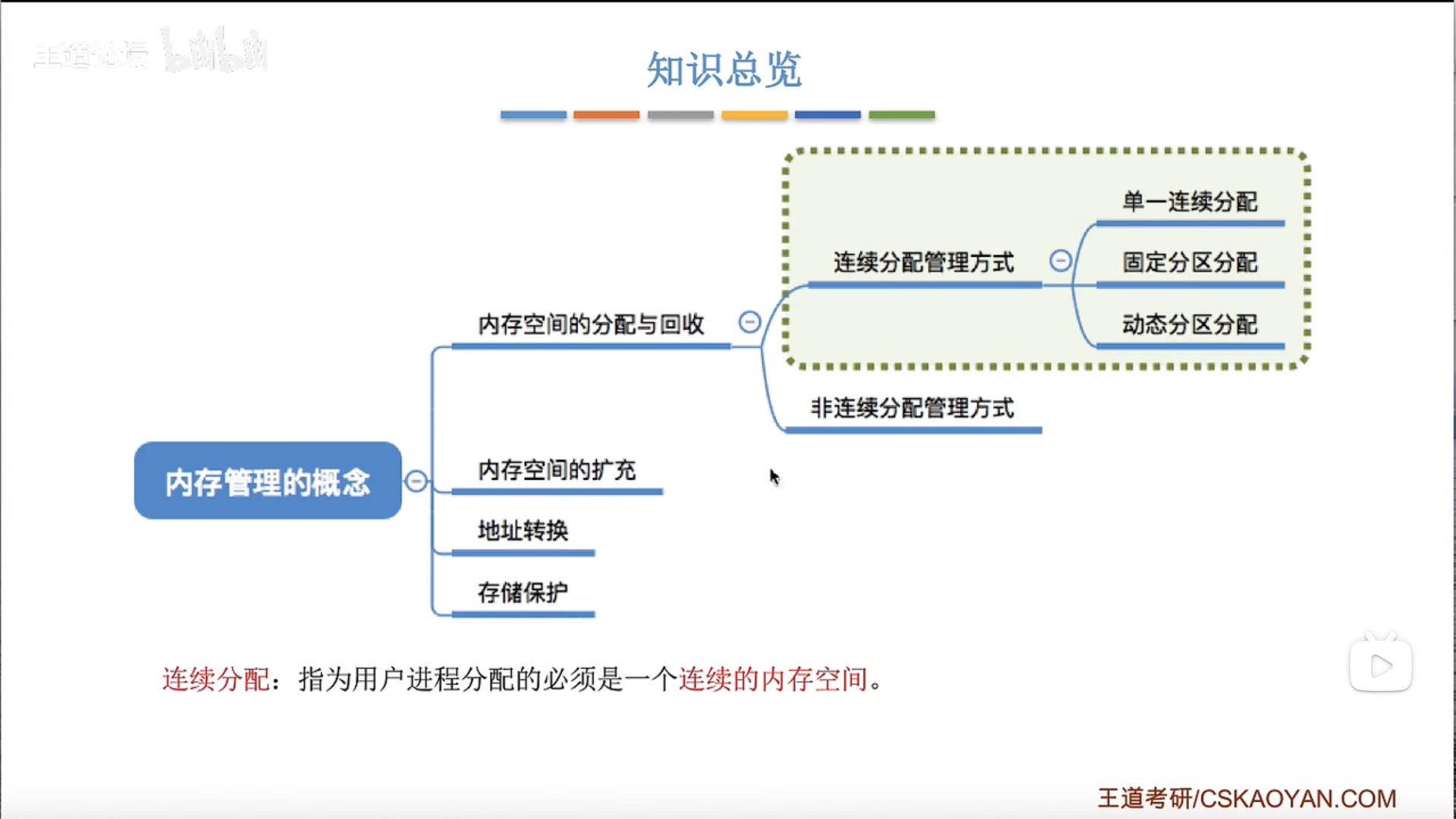
单一连续分配
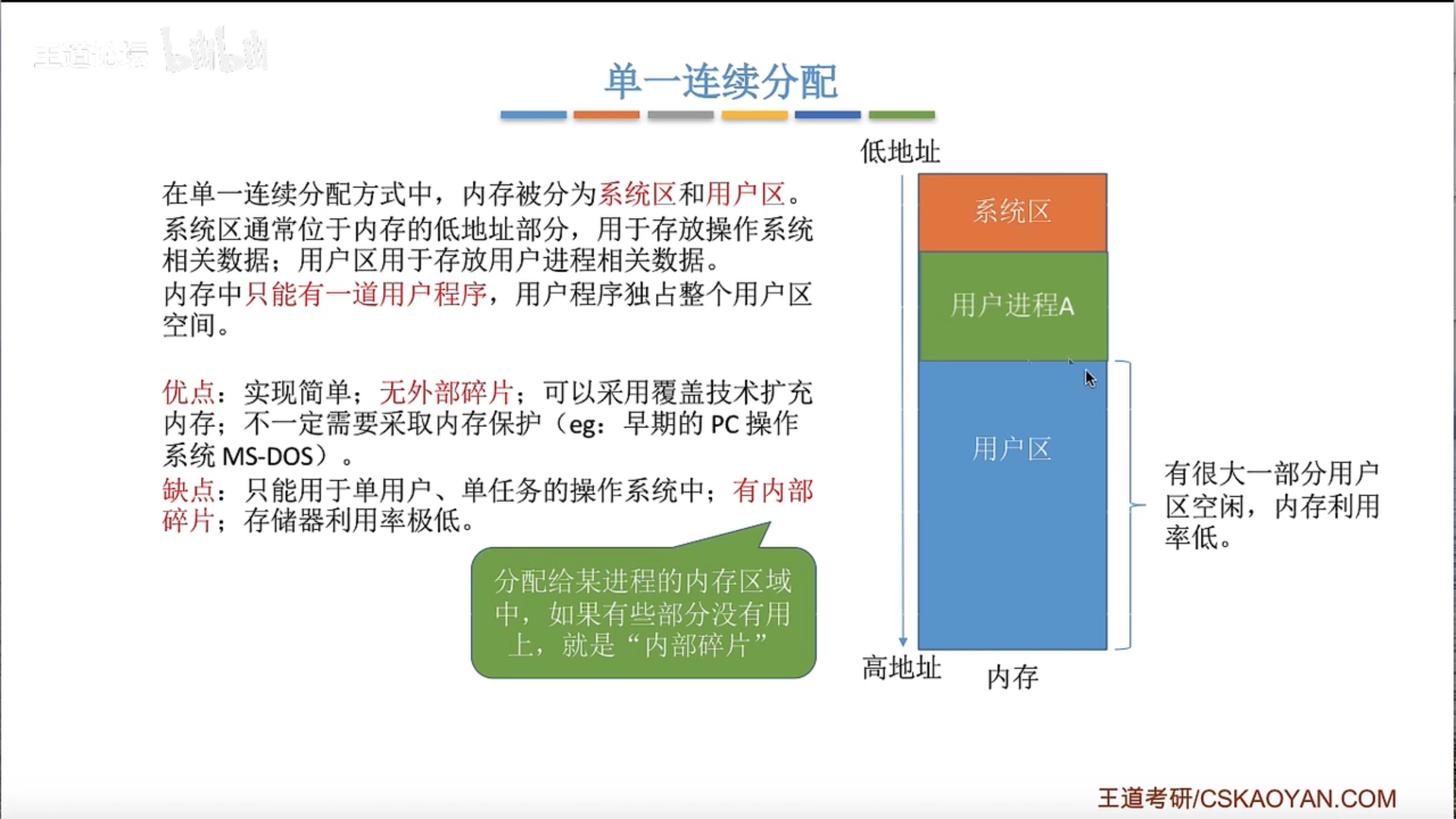
固定分区分配

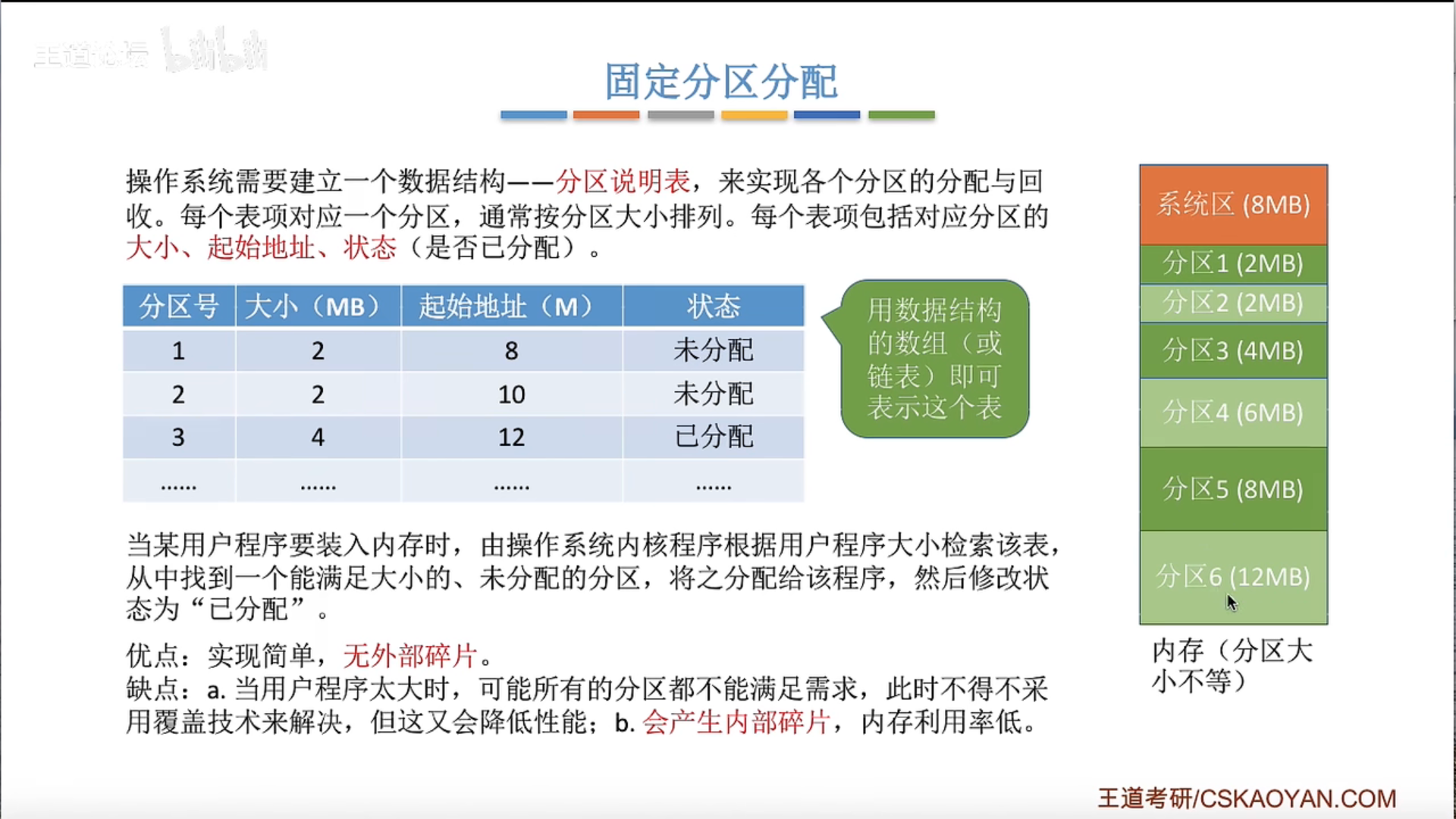
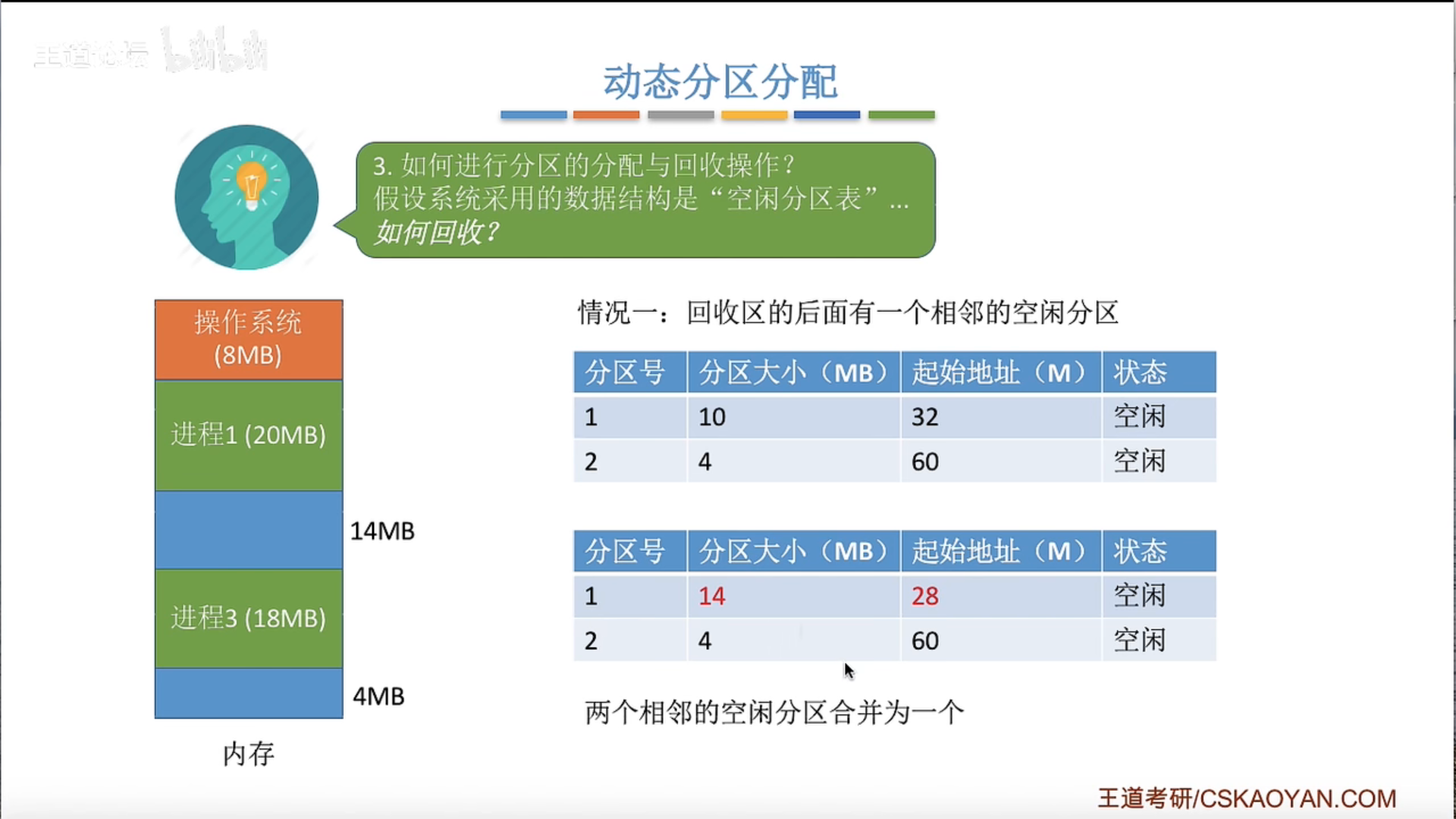
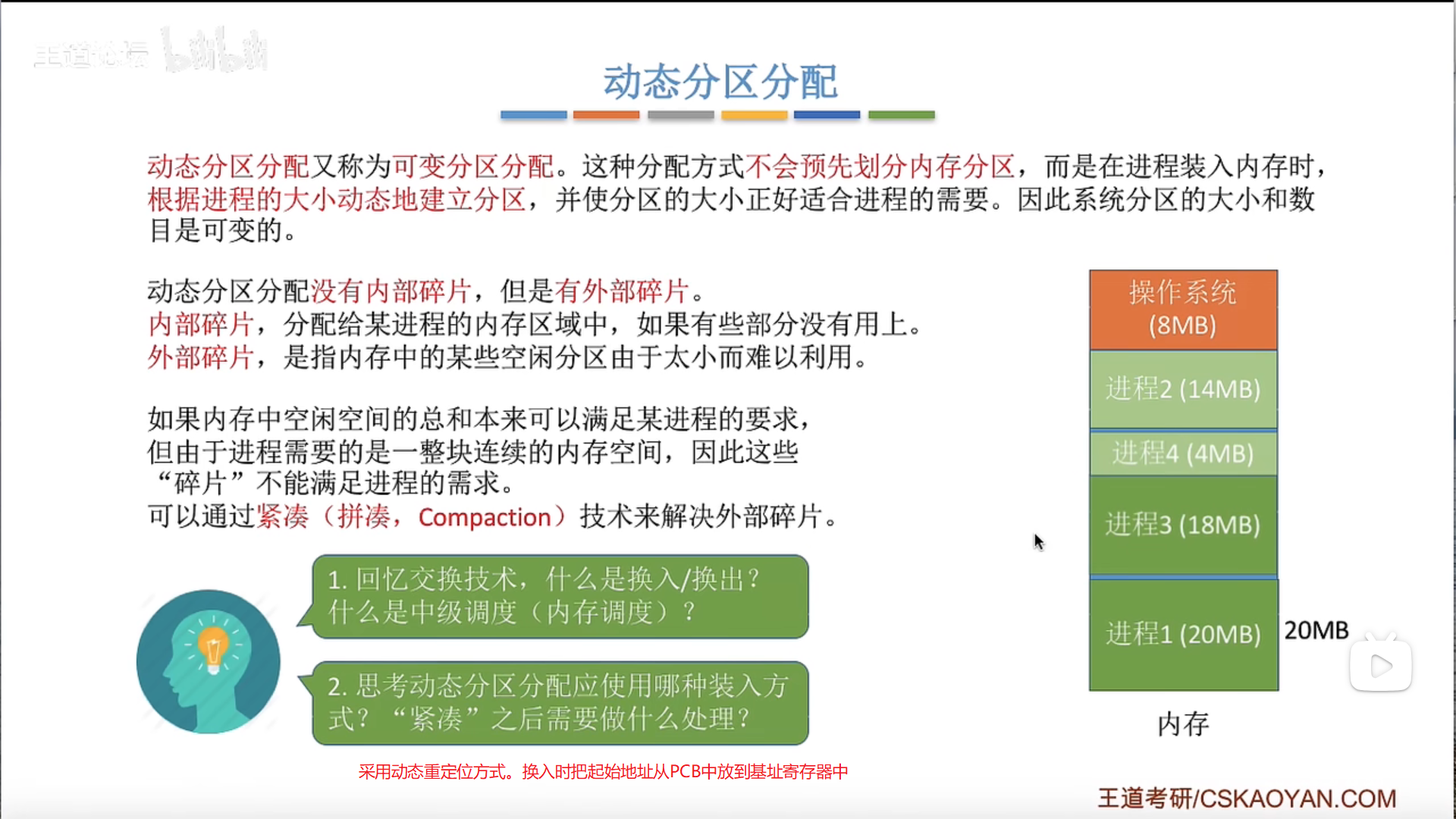
动态分区分配及算法

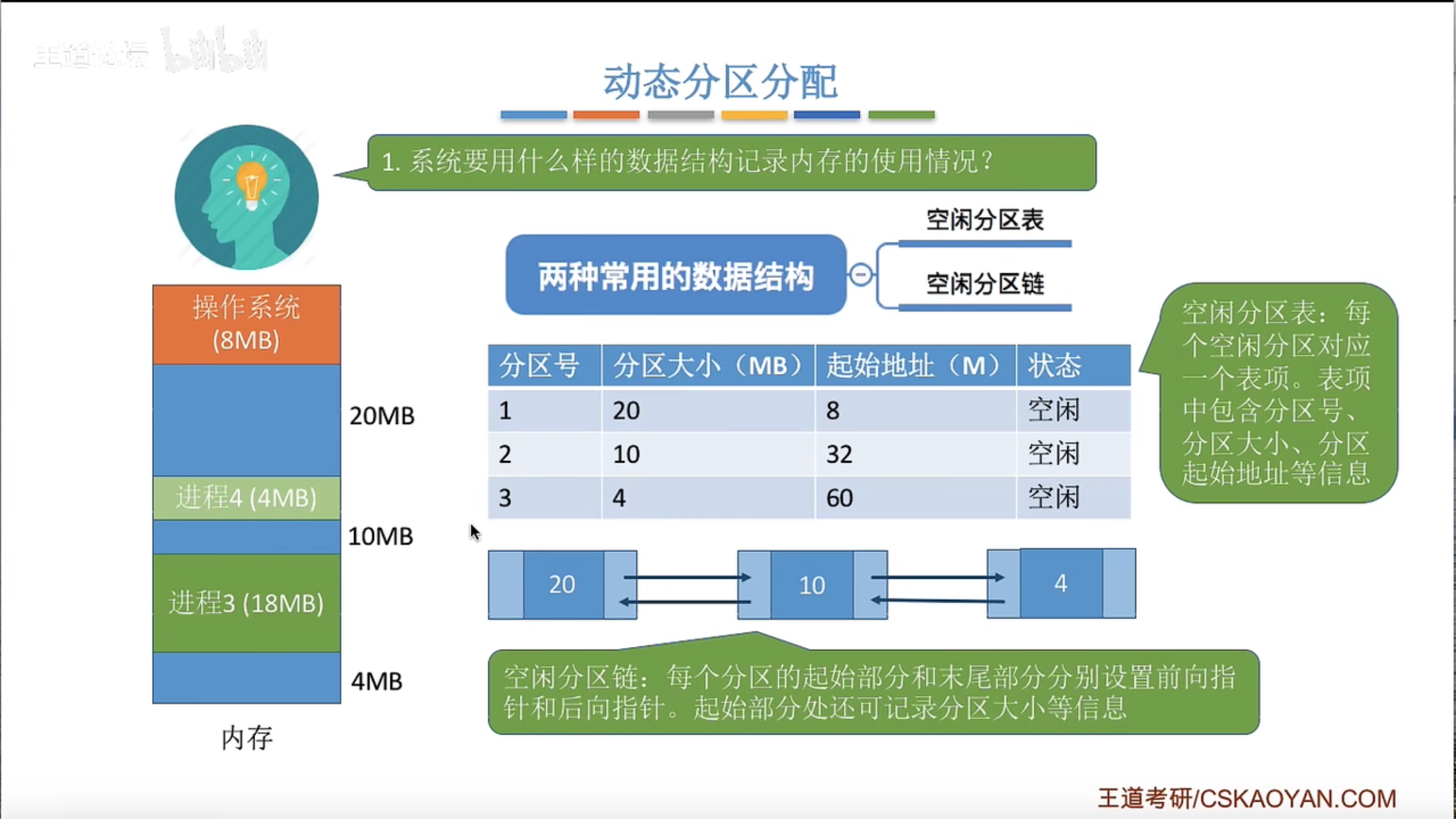
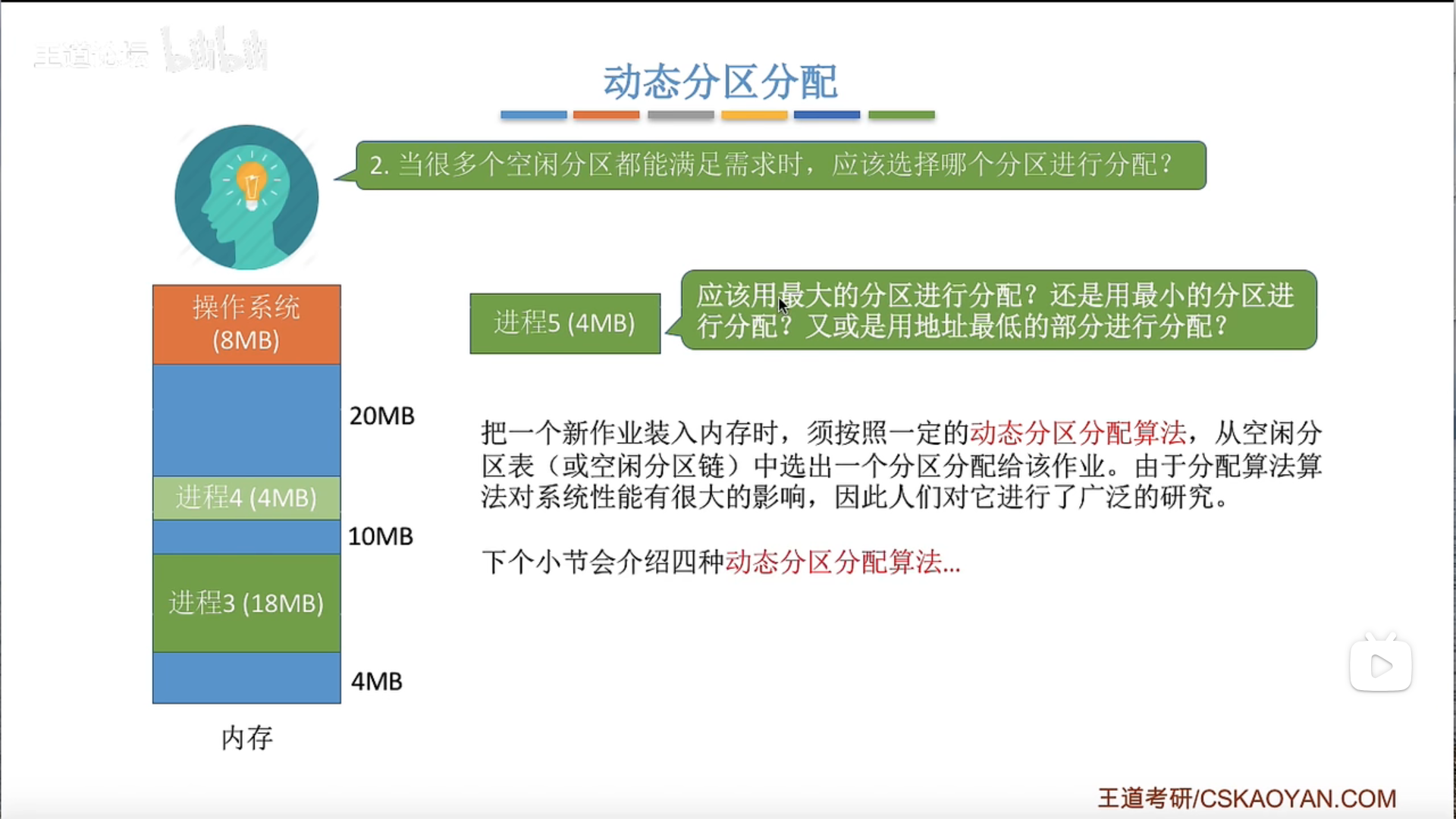

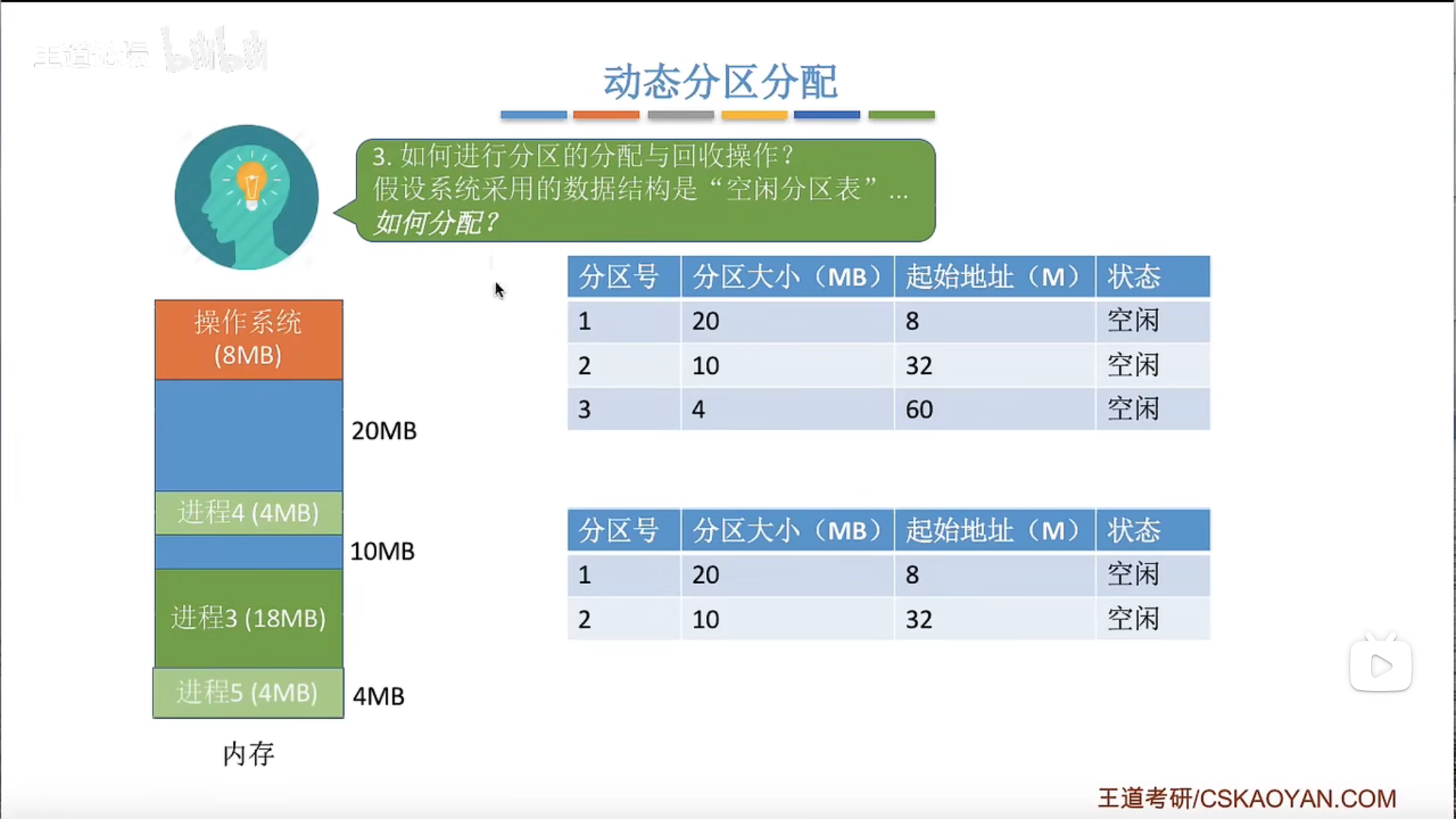
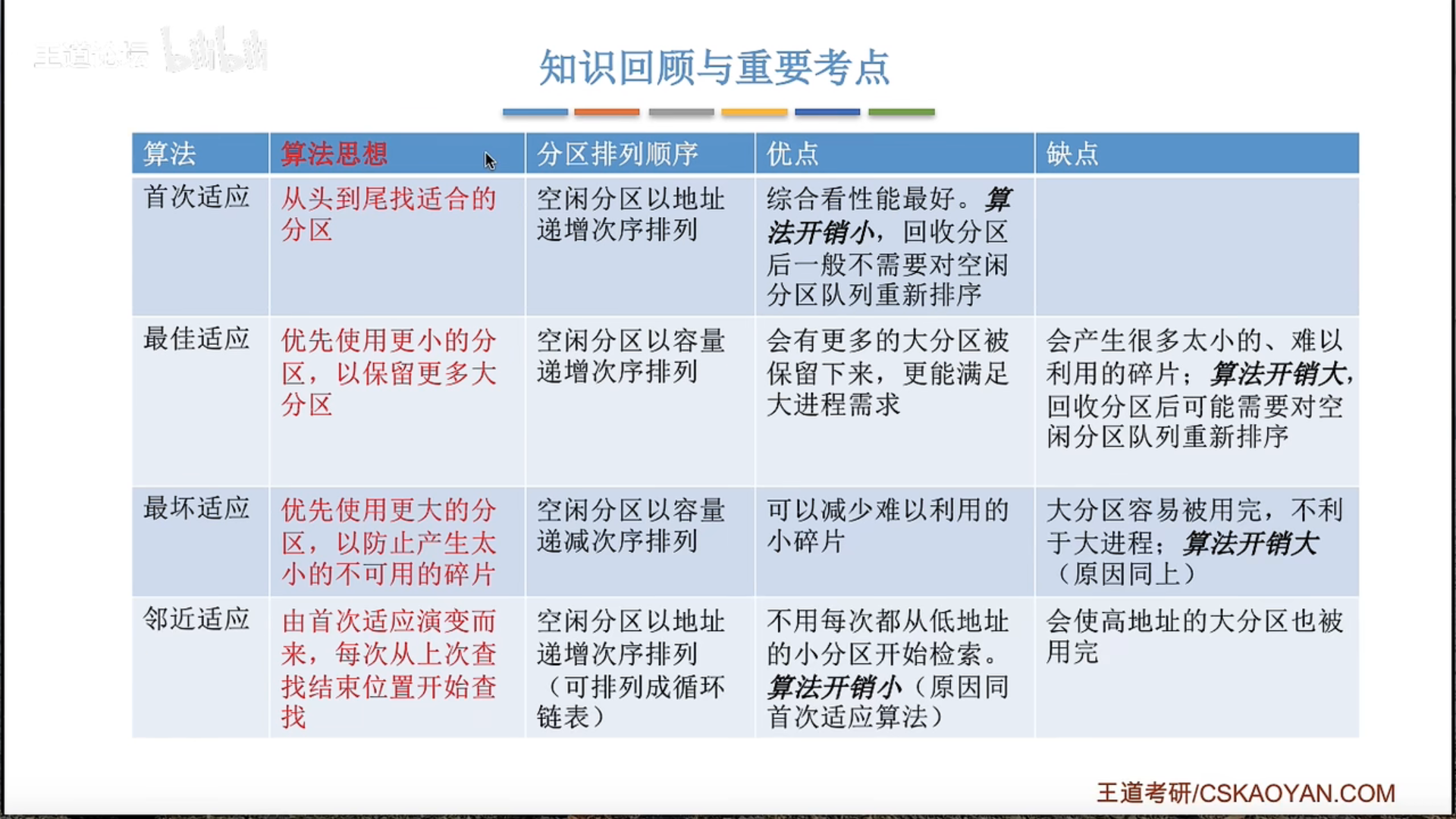
如何回收?如果有相邻的空闲区域就合并
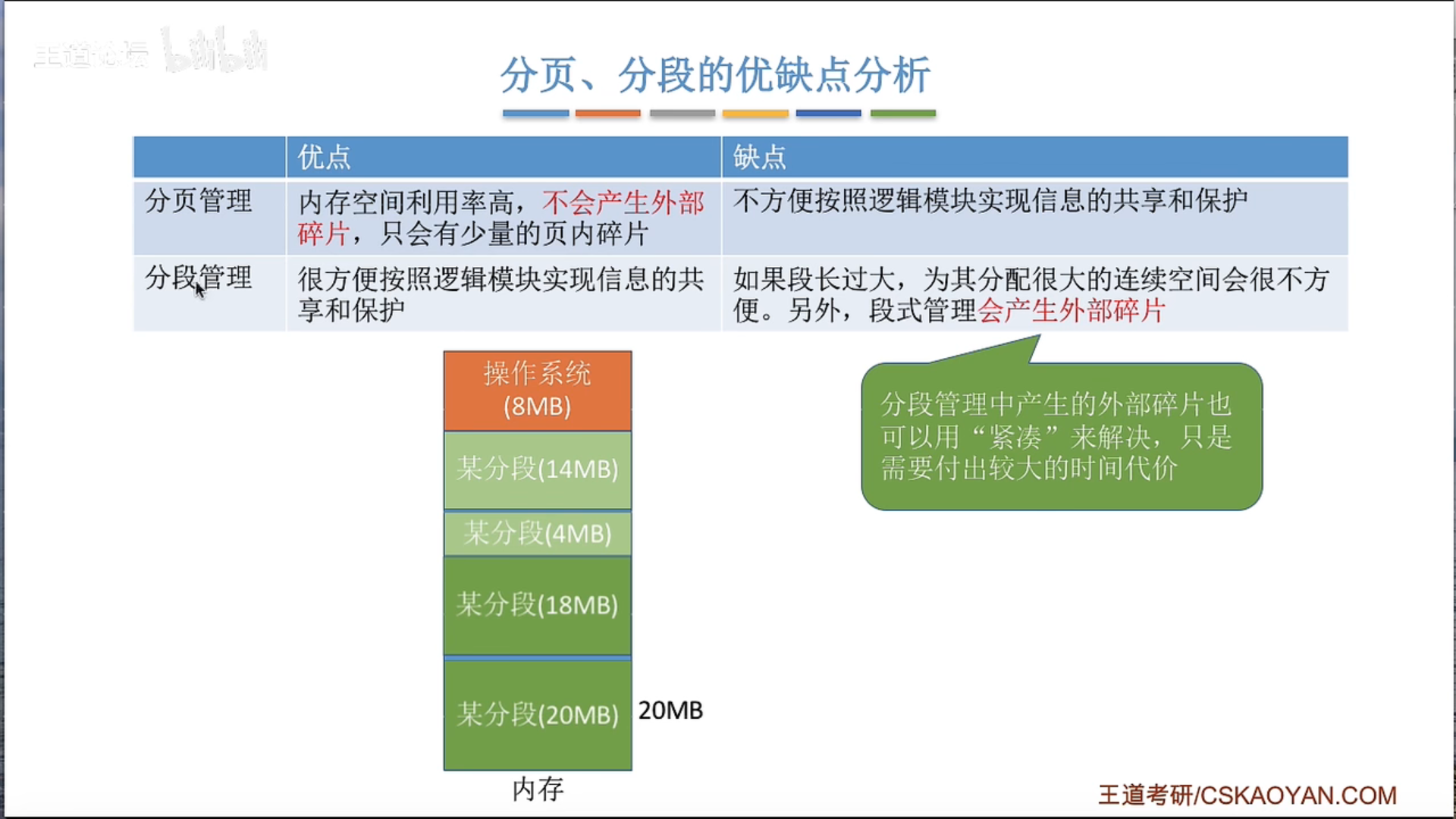
内部碎片与外部碎片
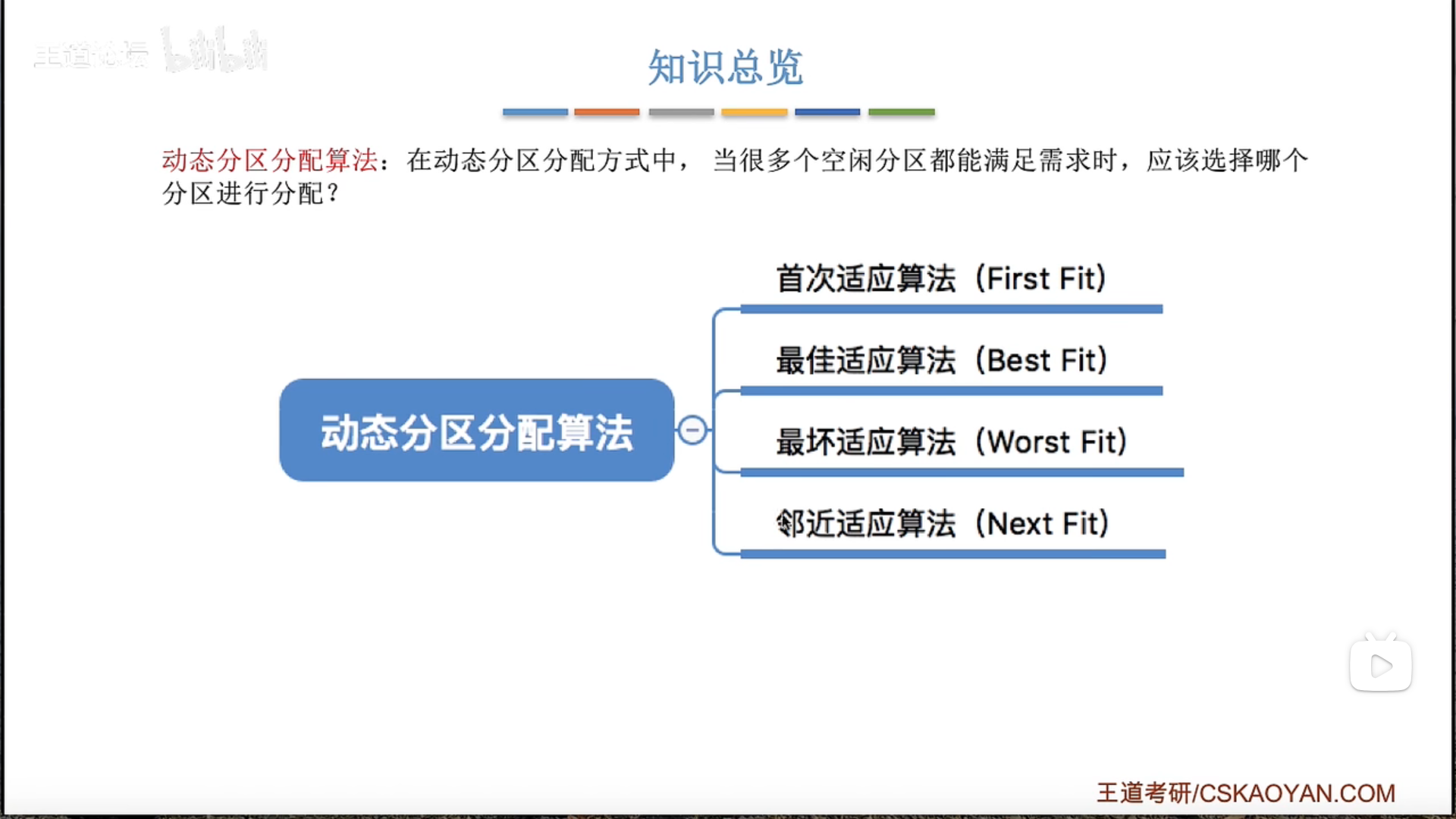
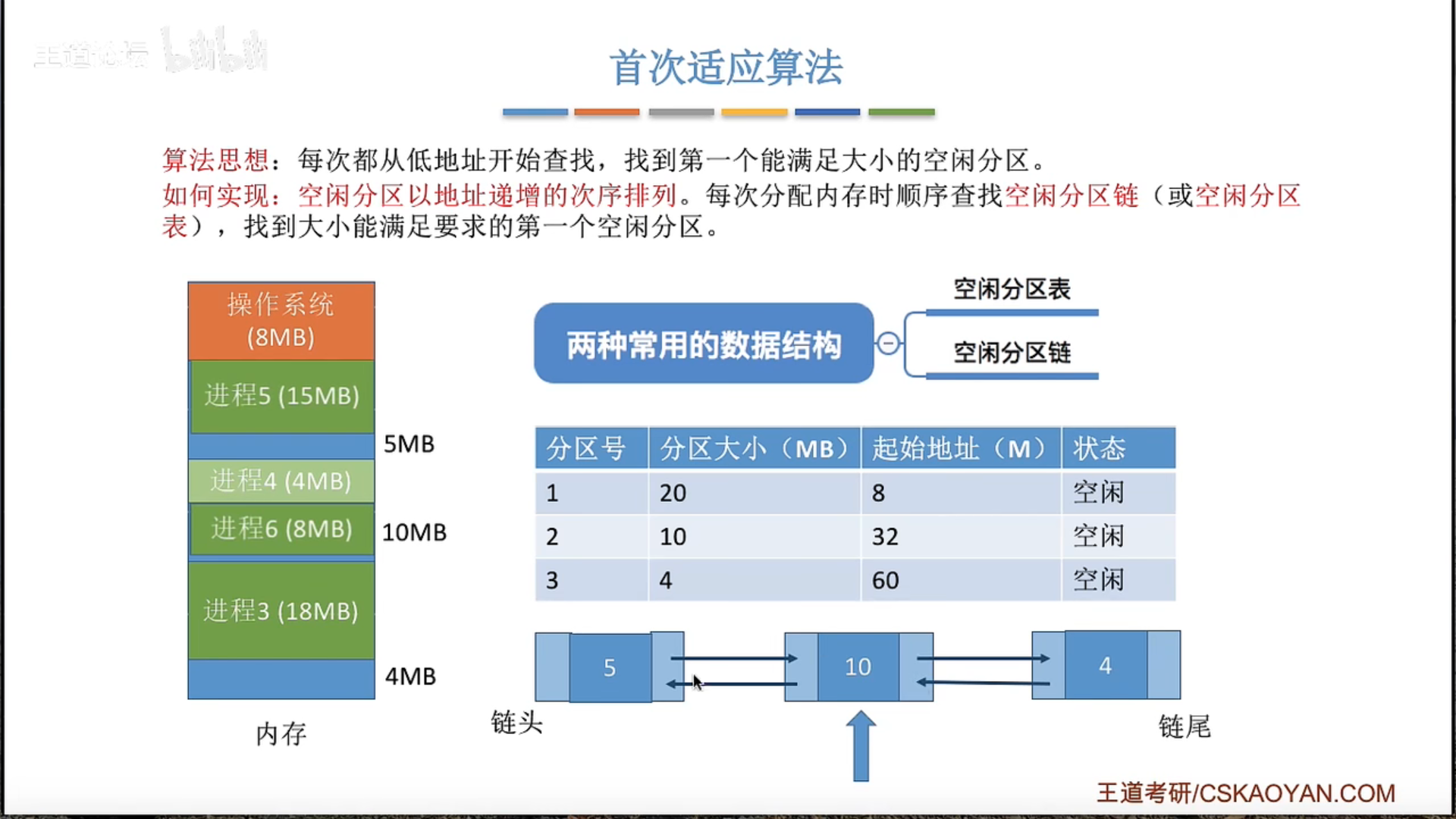
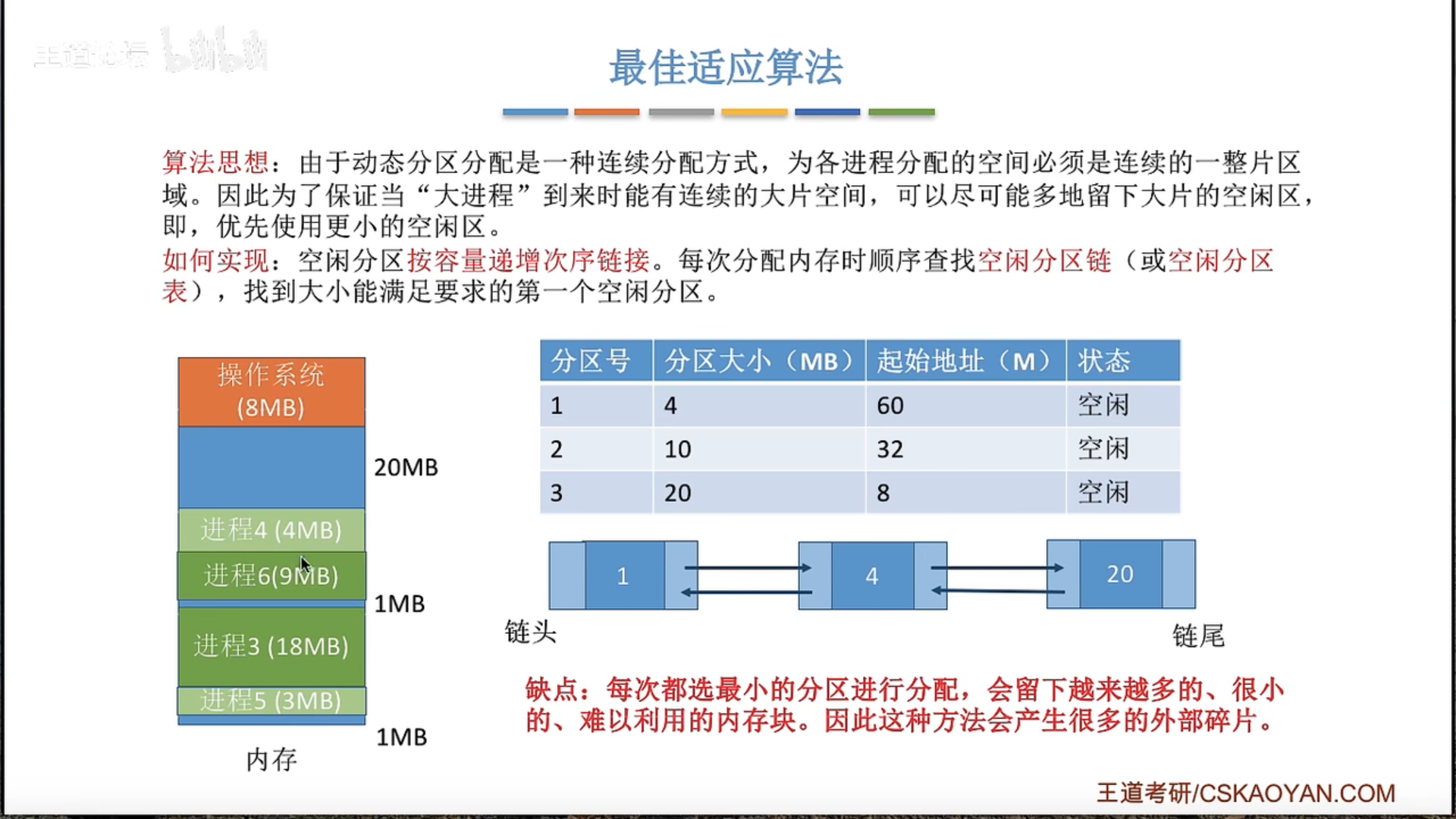
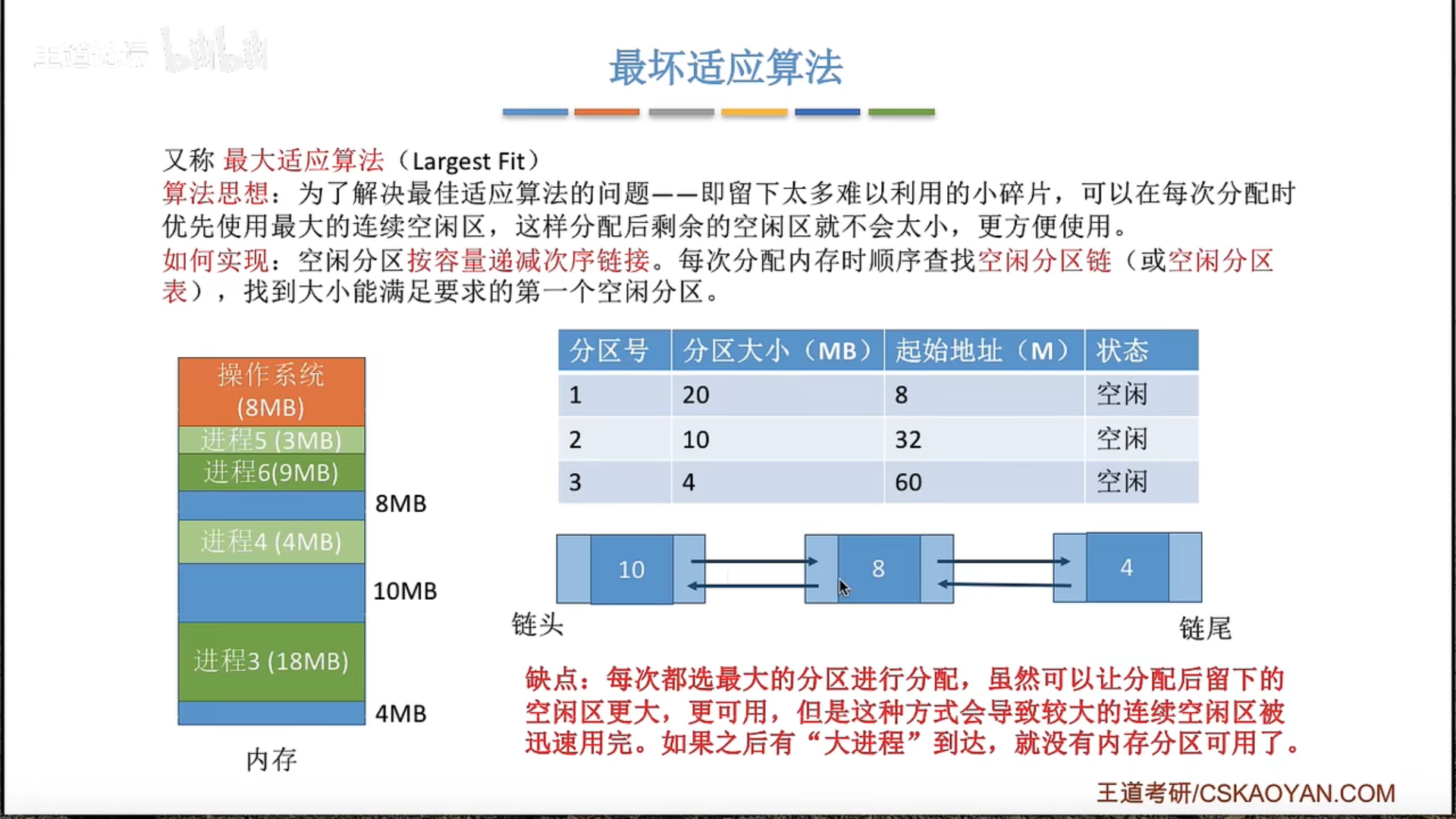
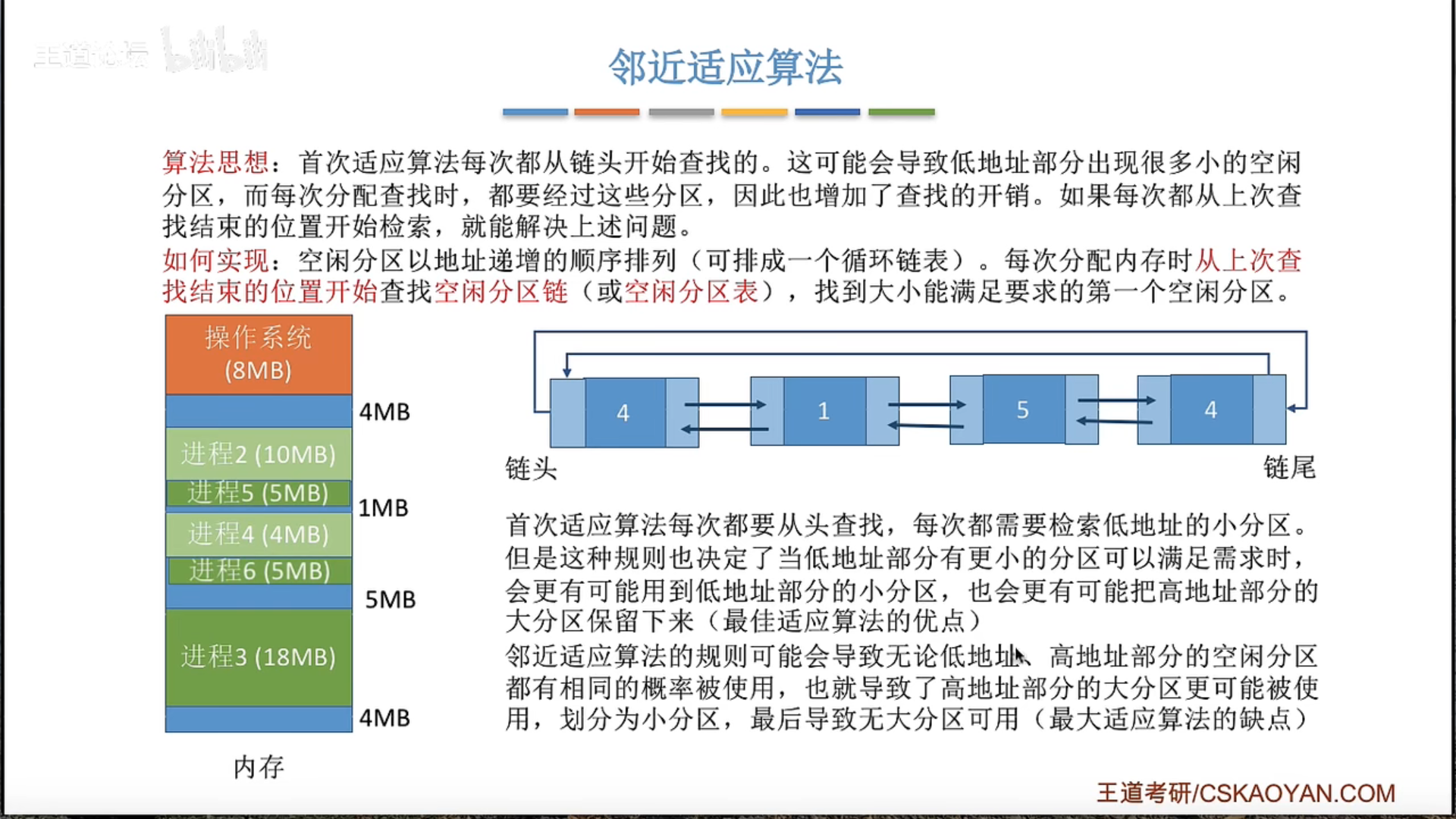
首次适应算法效果最好
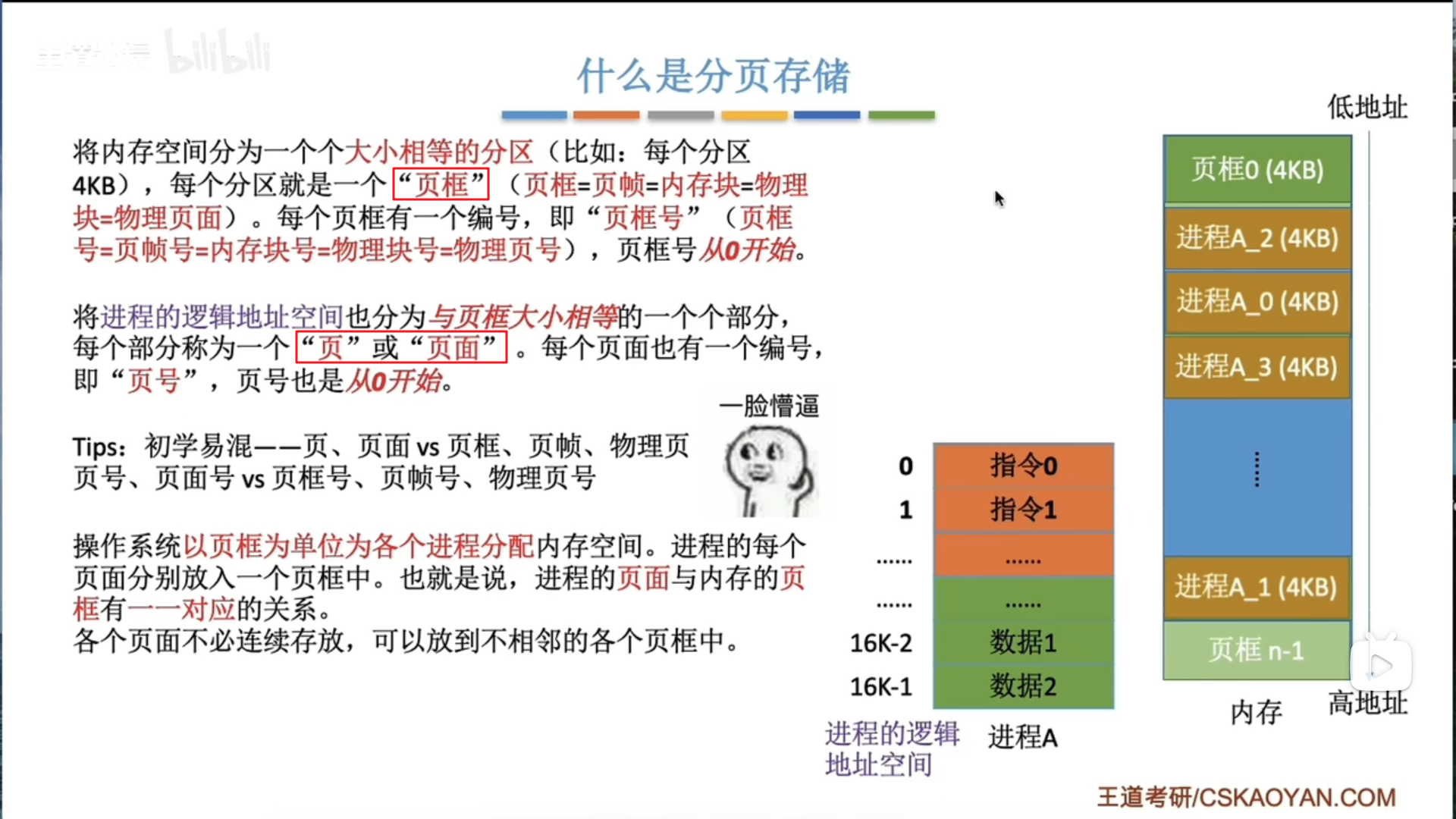
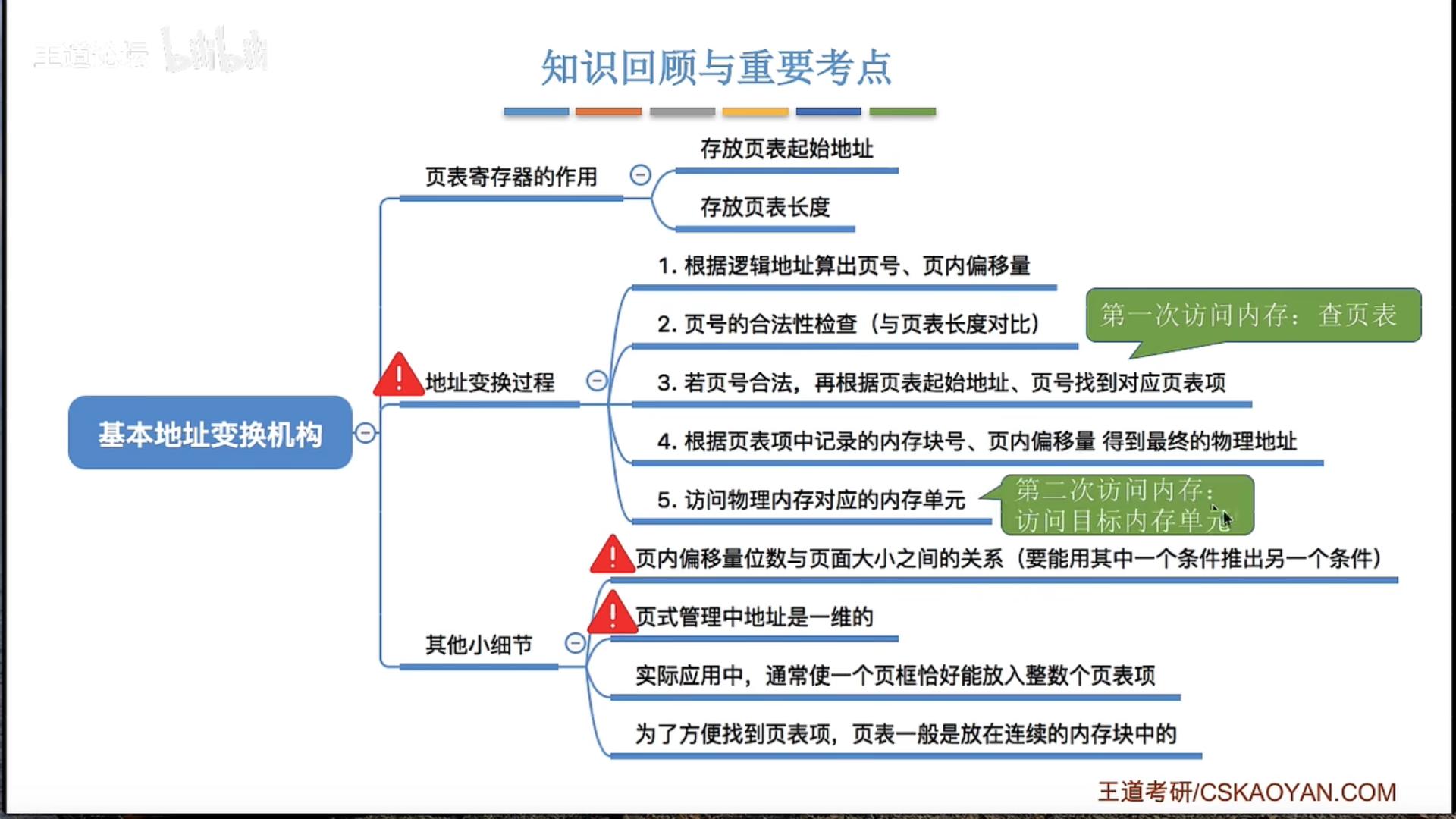
3.1.4 基本分页存储管理
基本概念和地址转换
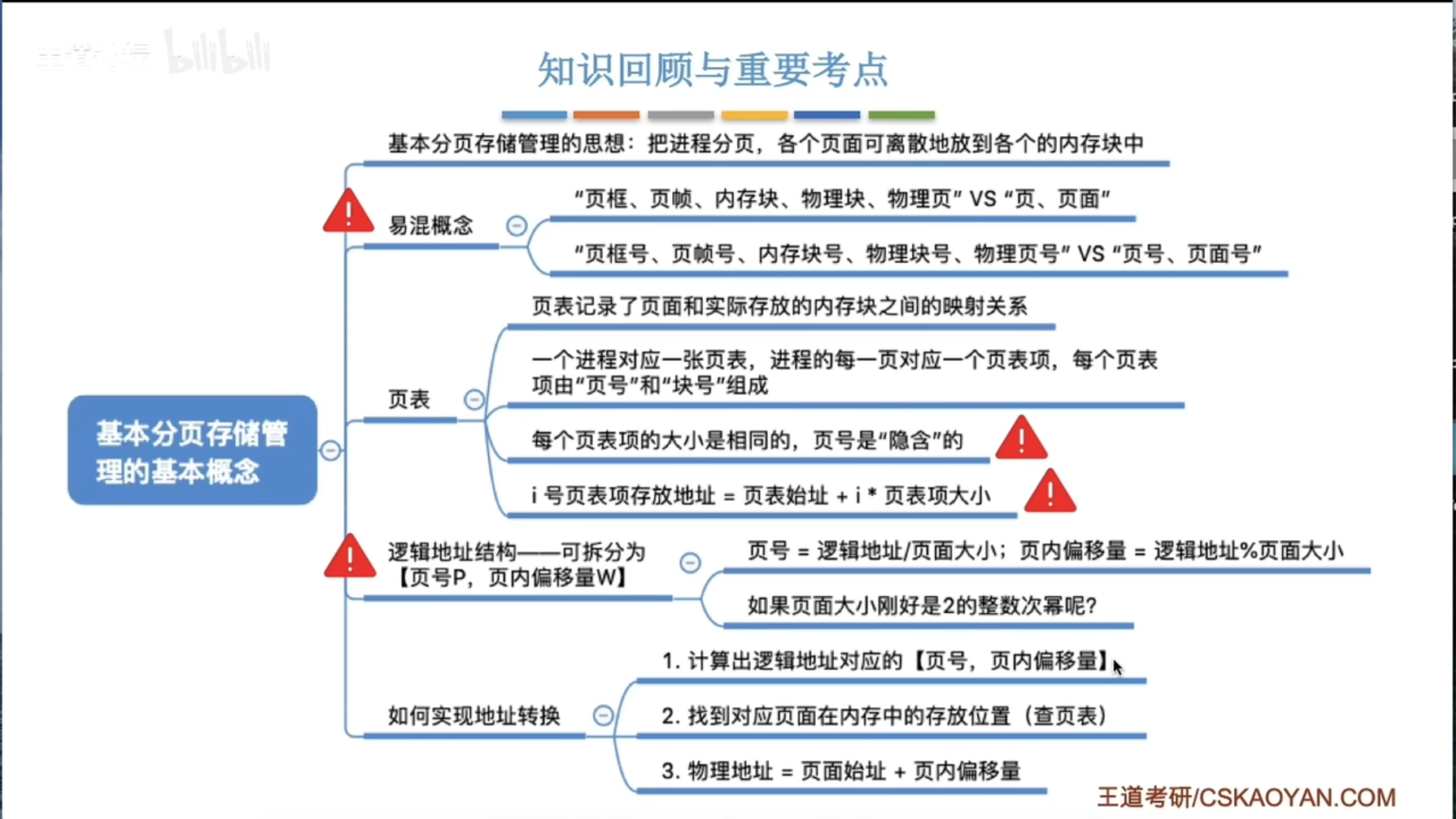
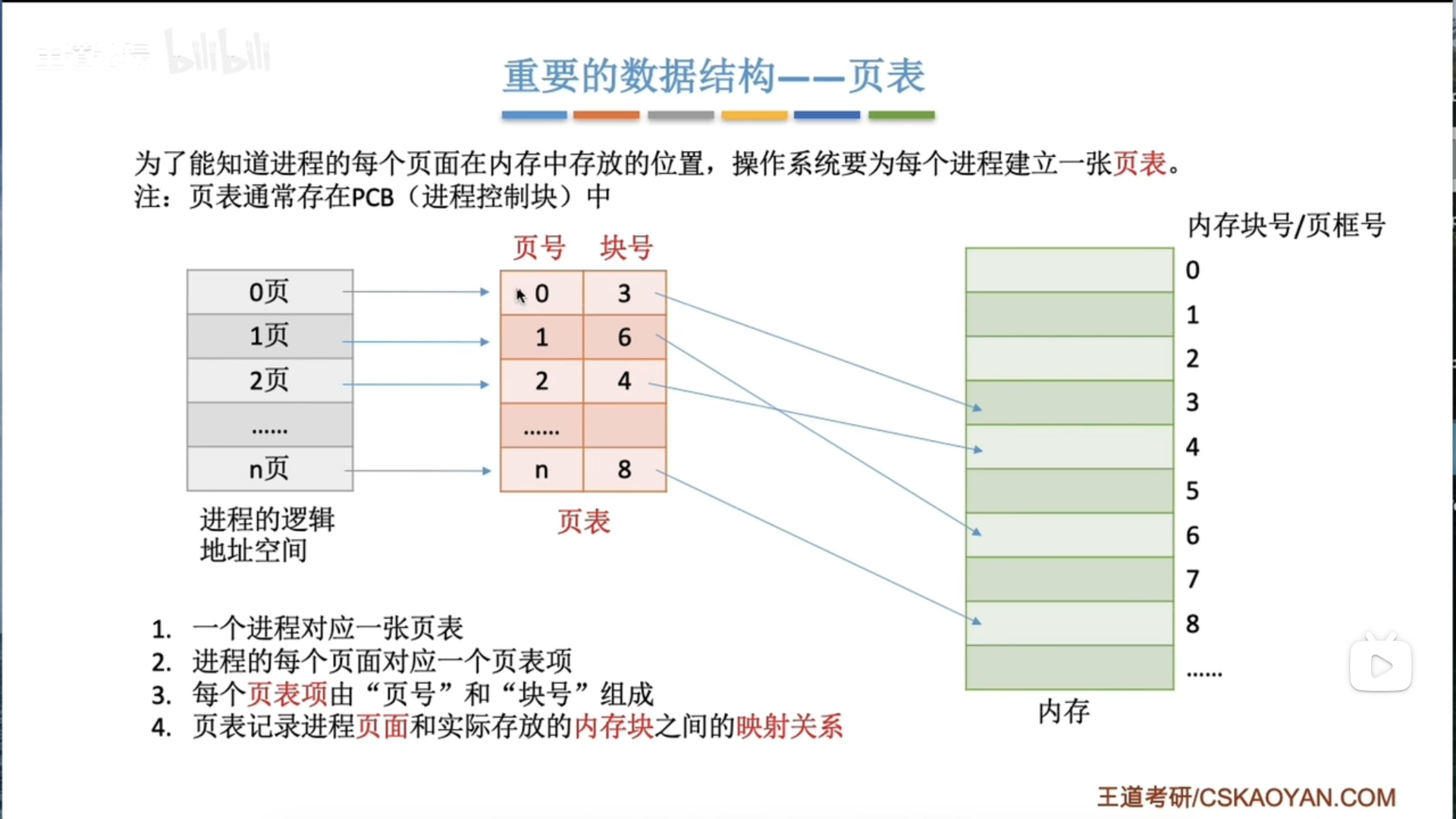
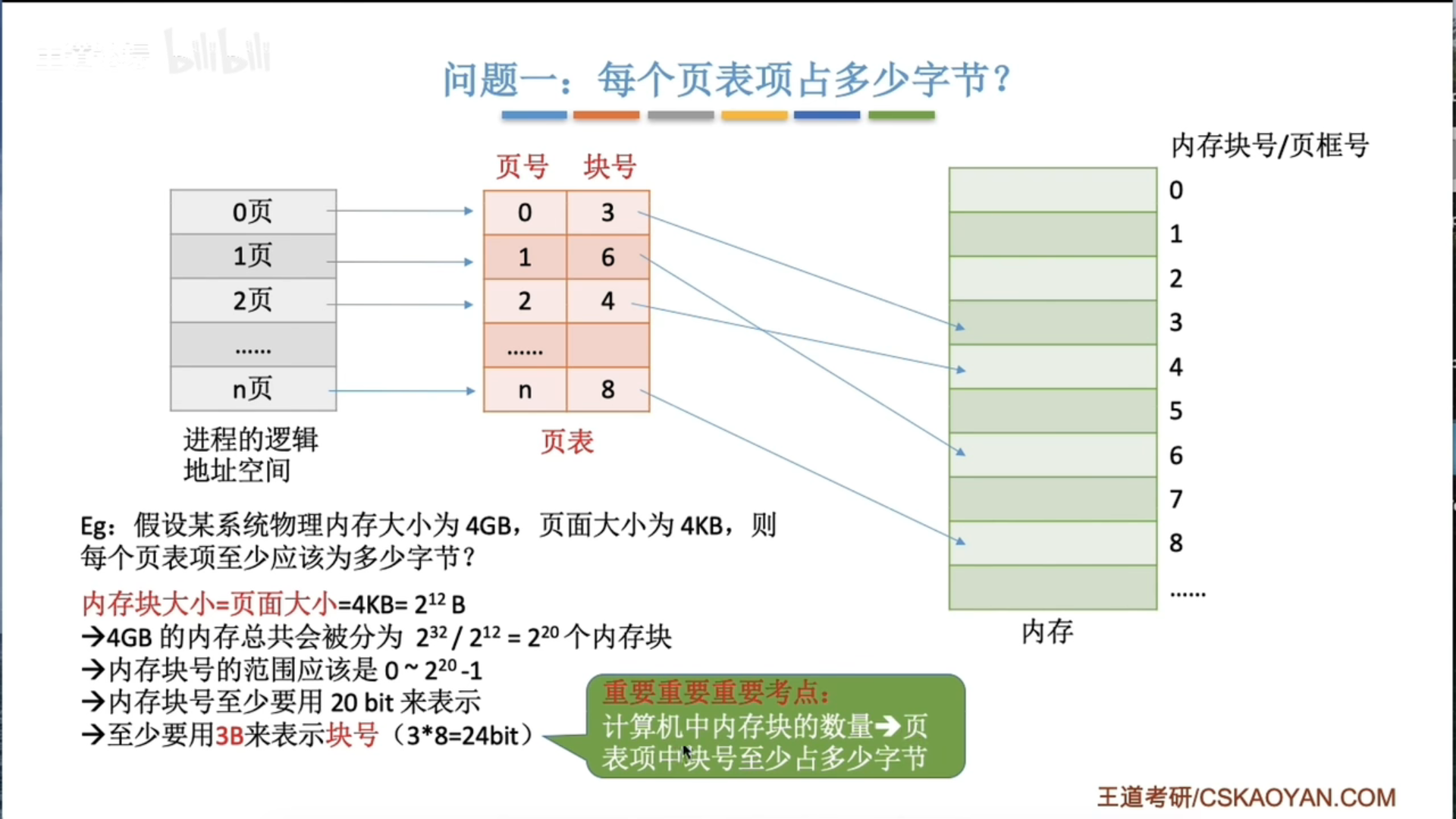

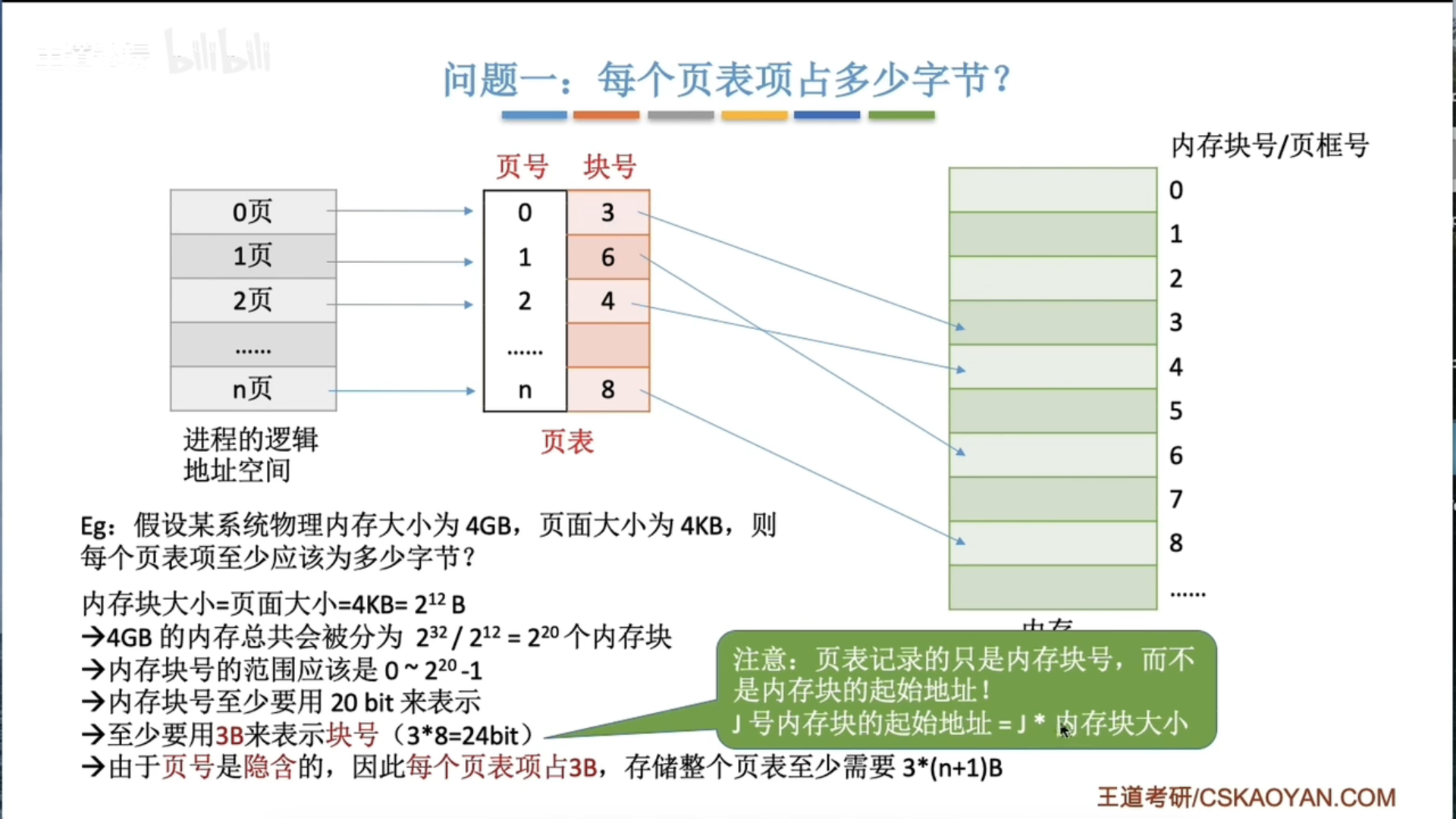







地址变换机构
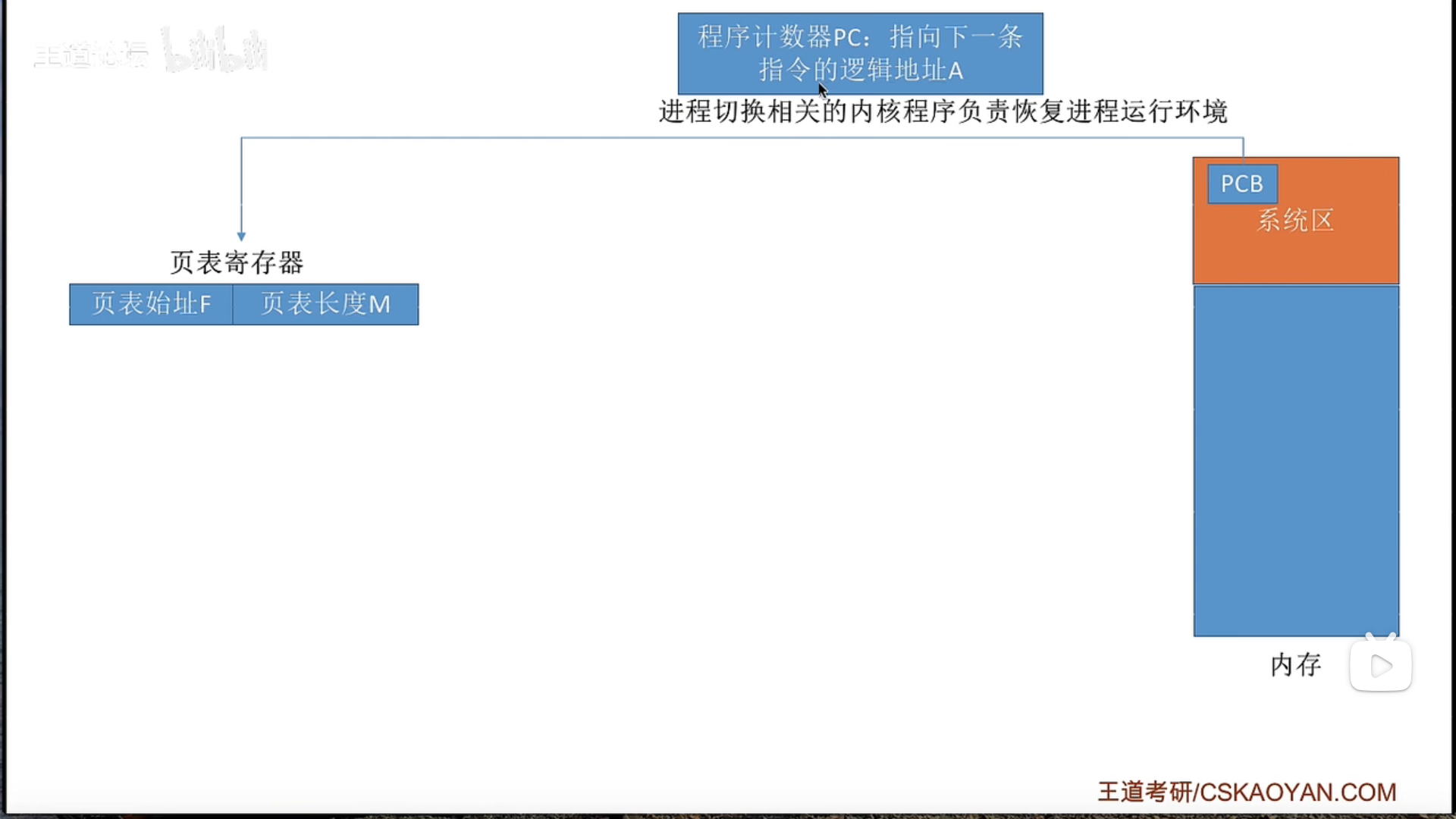




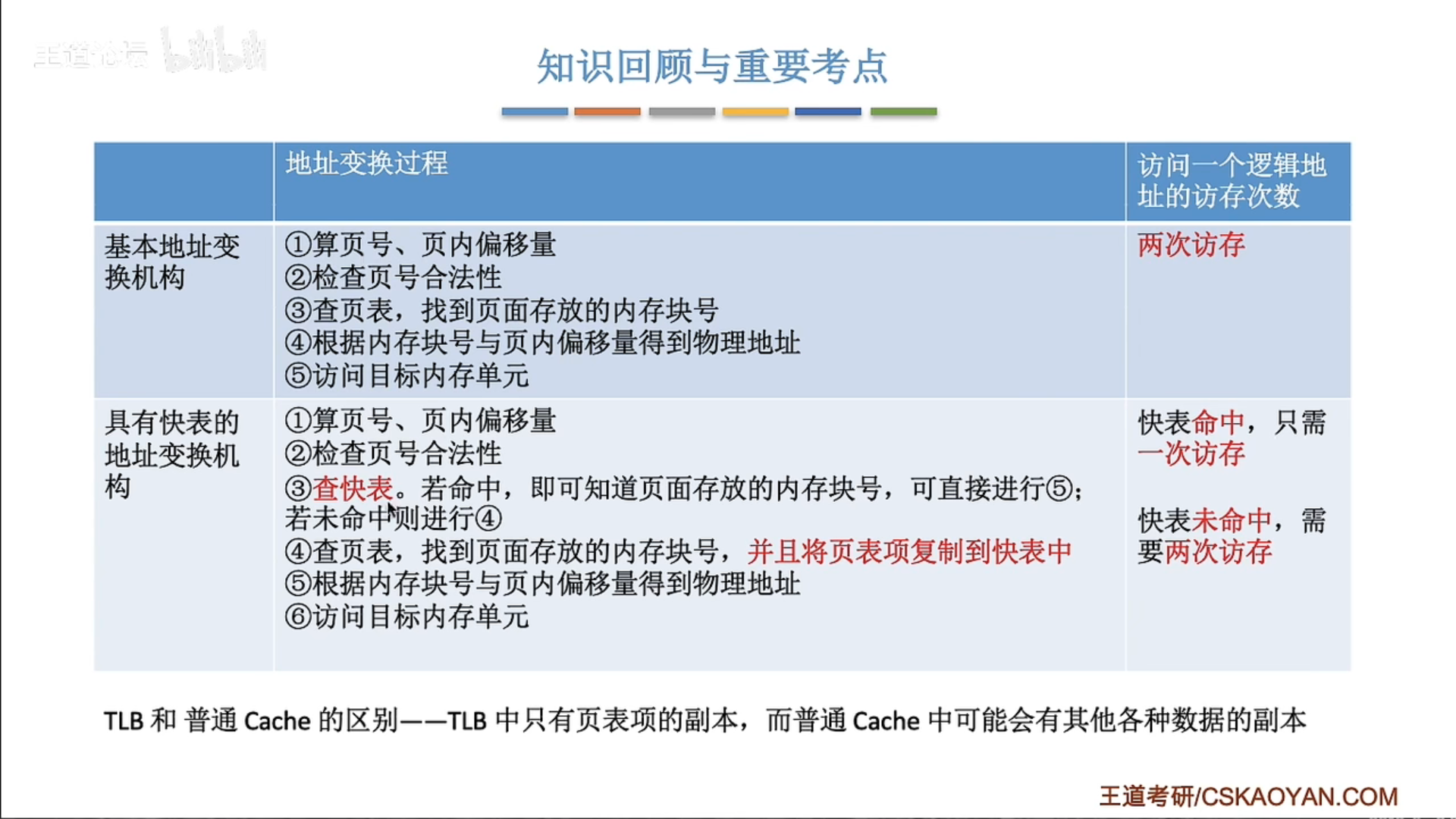
快表



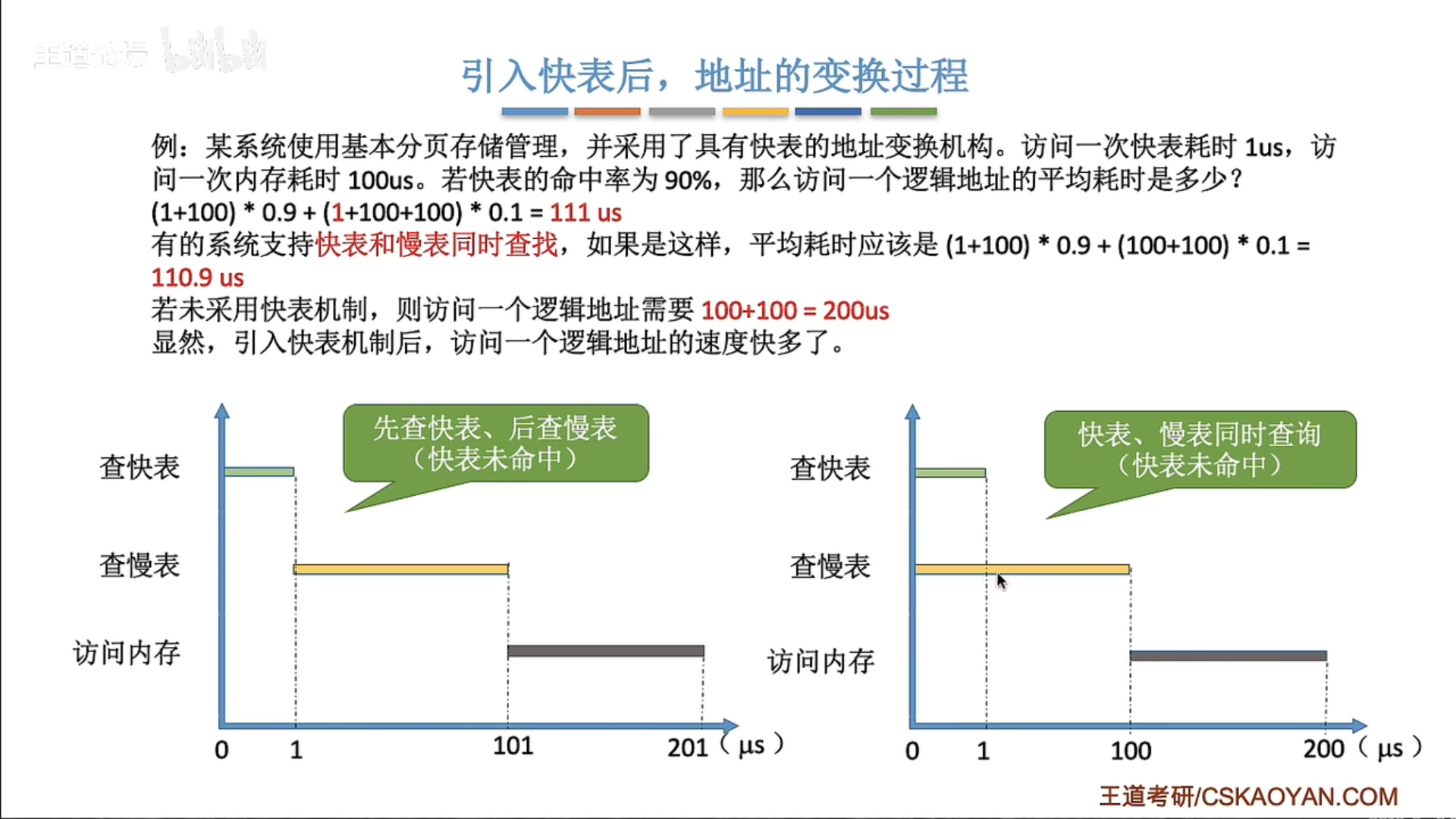
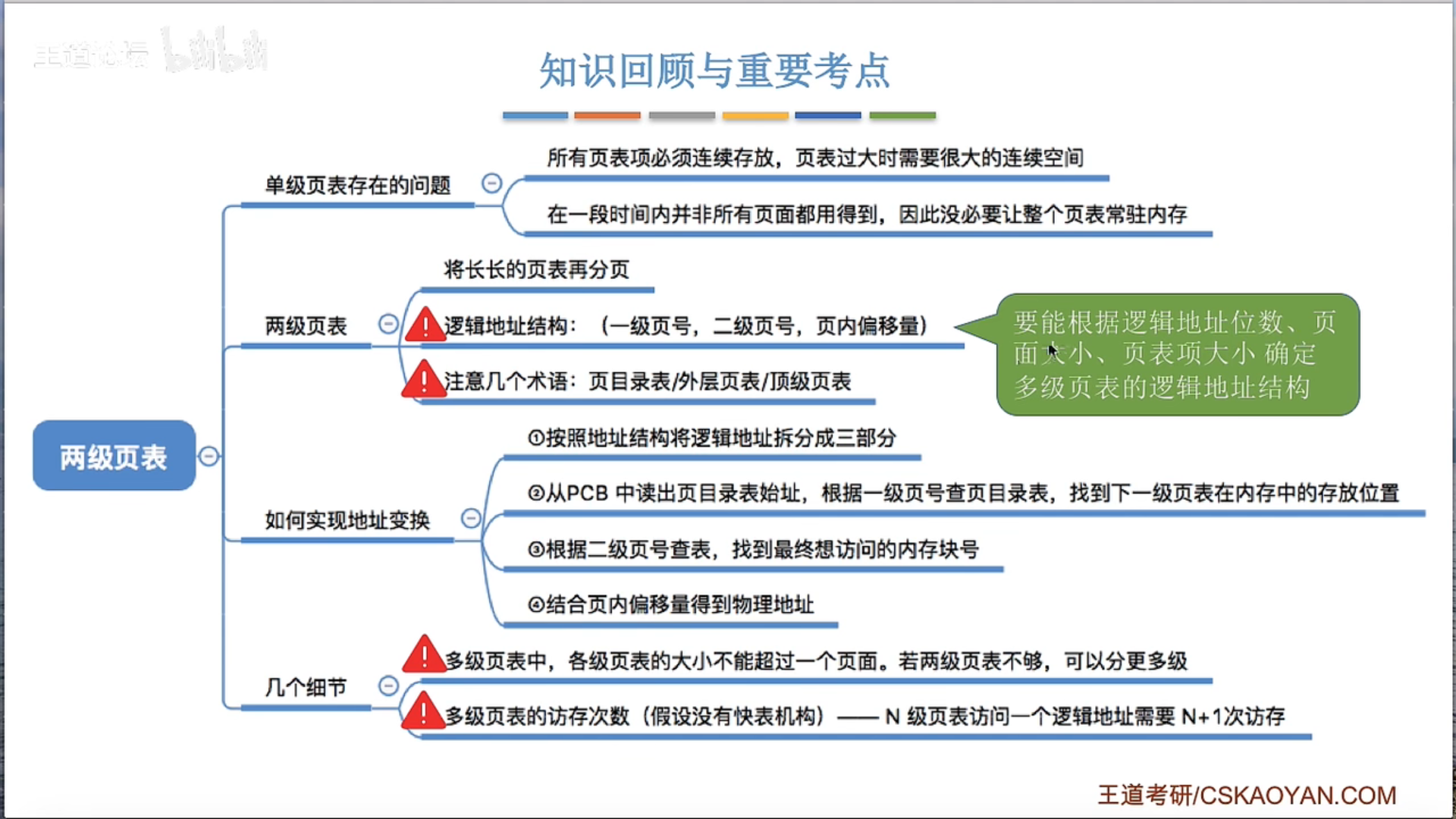
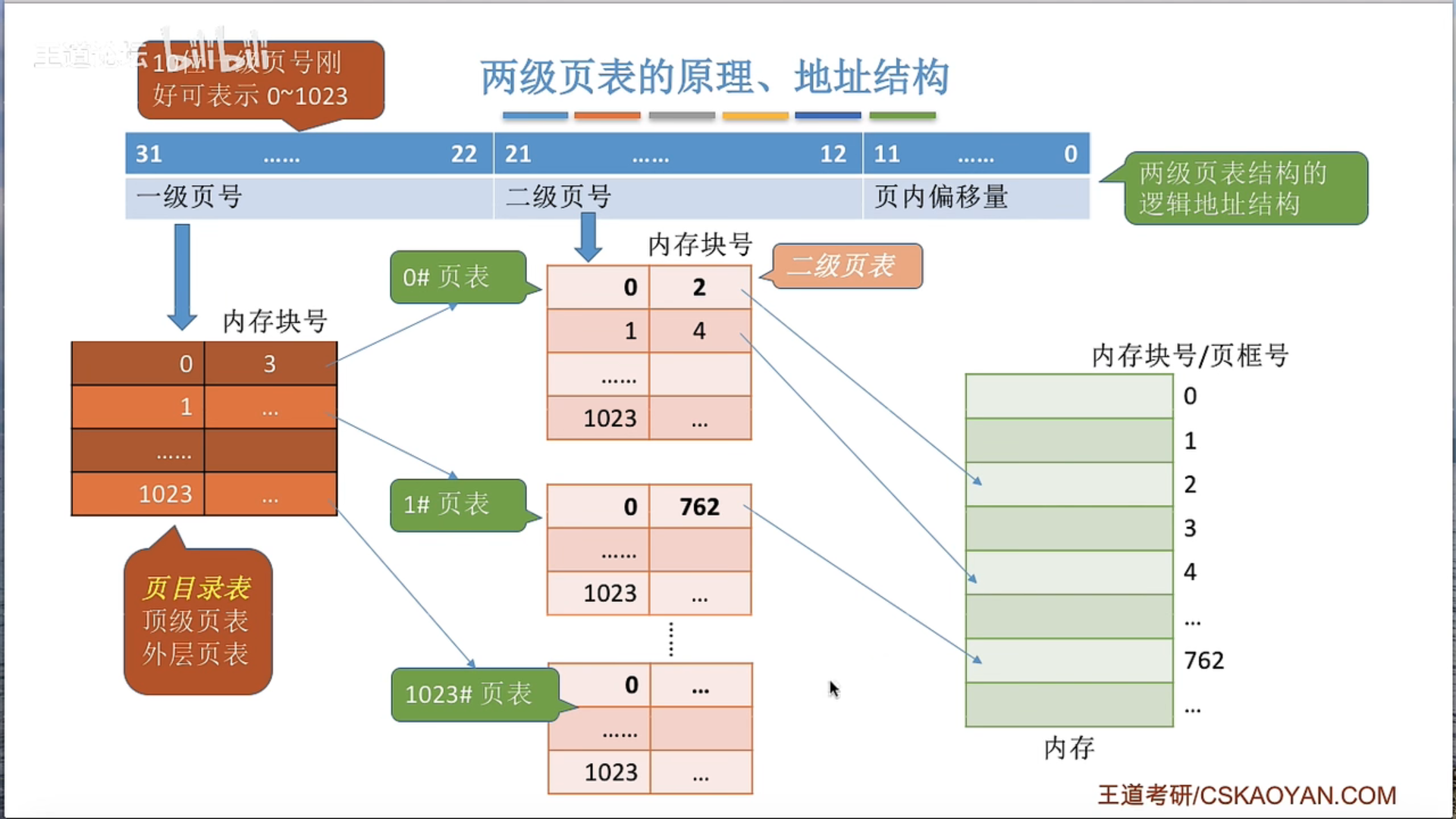
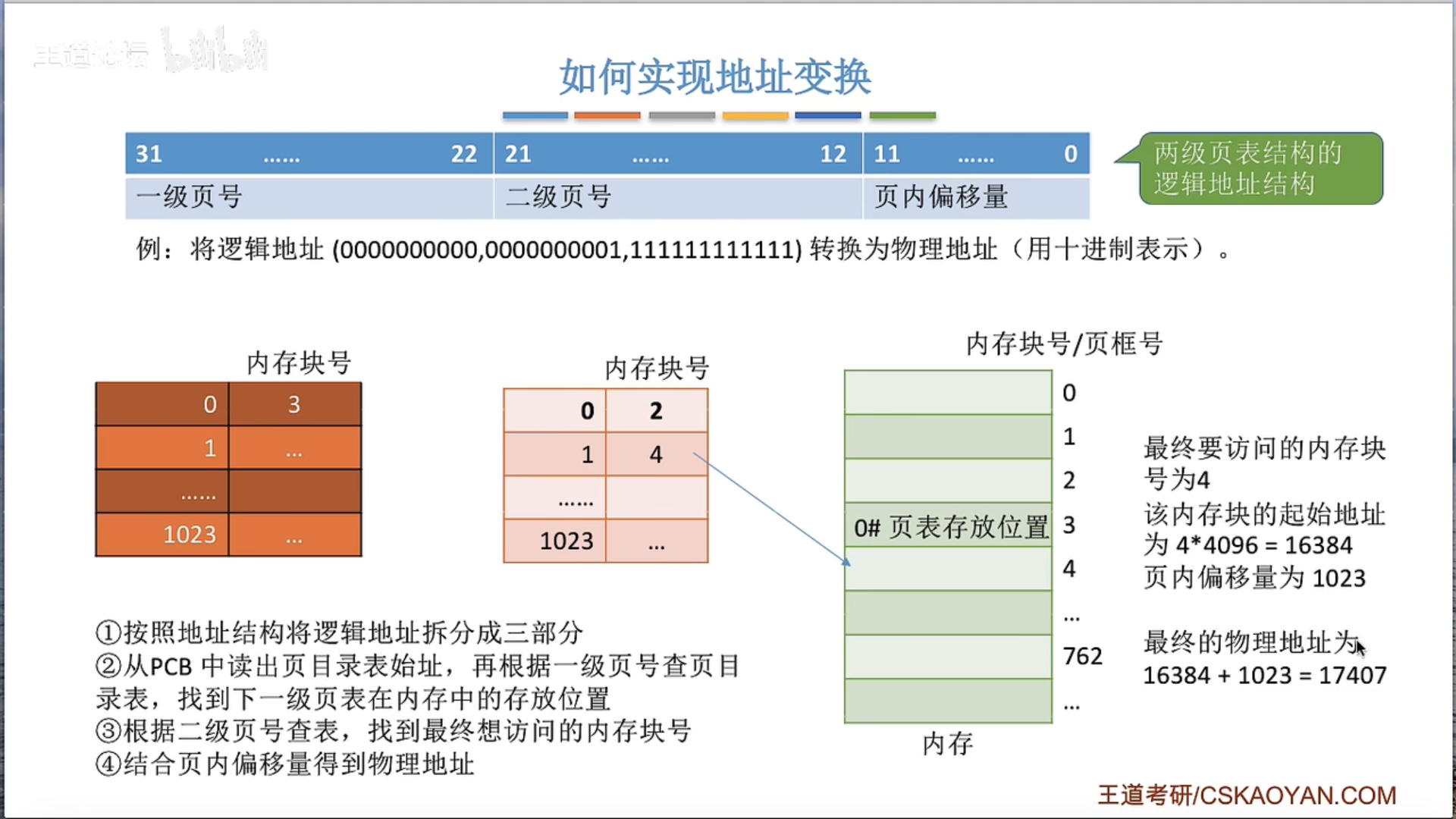
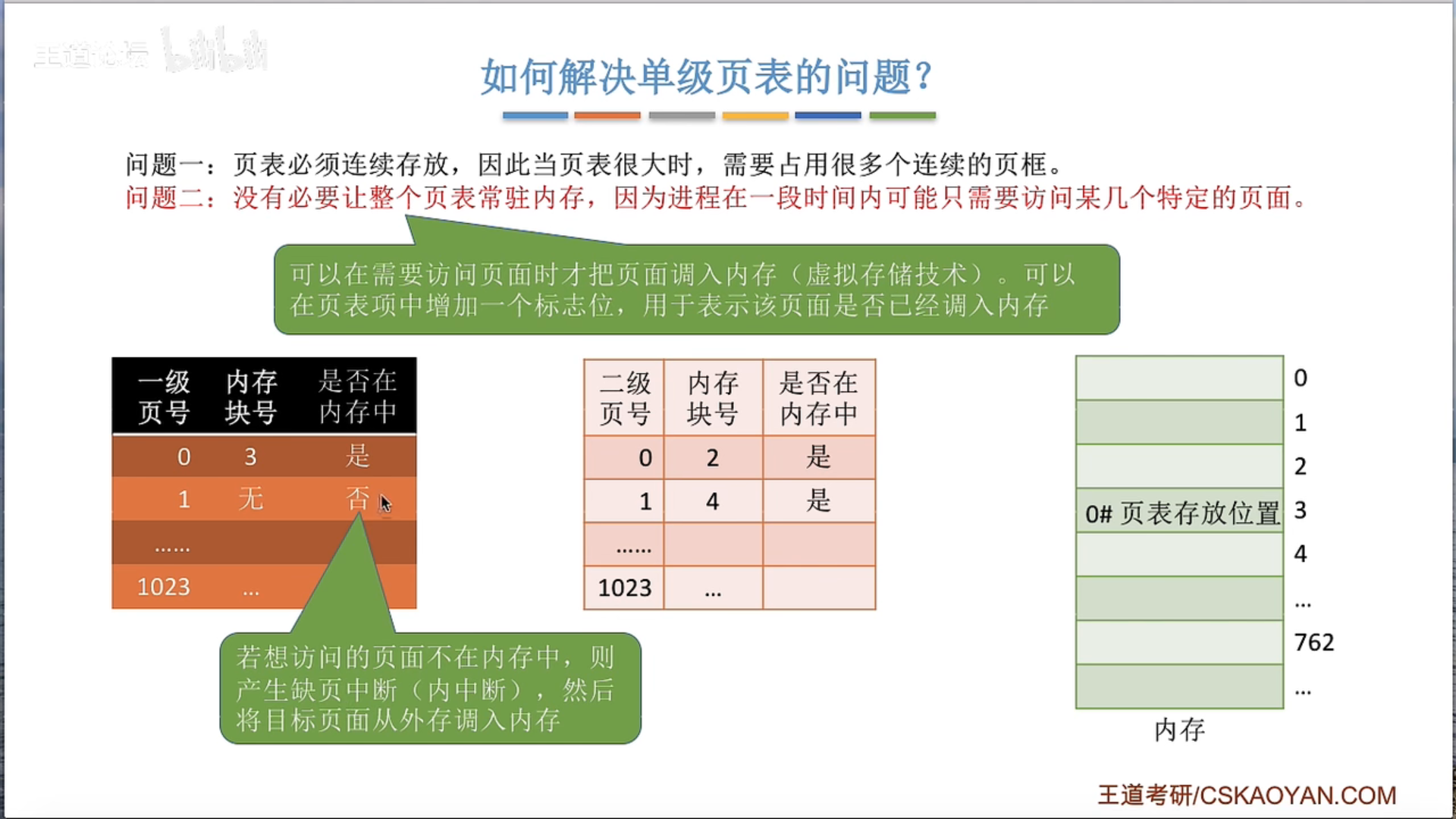
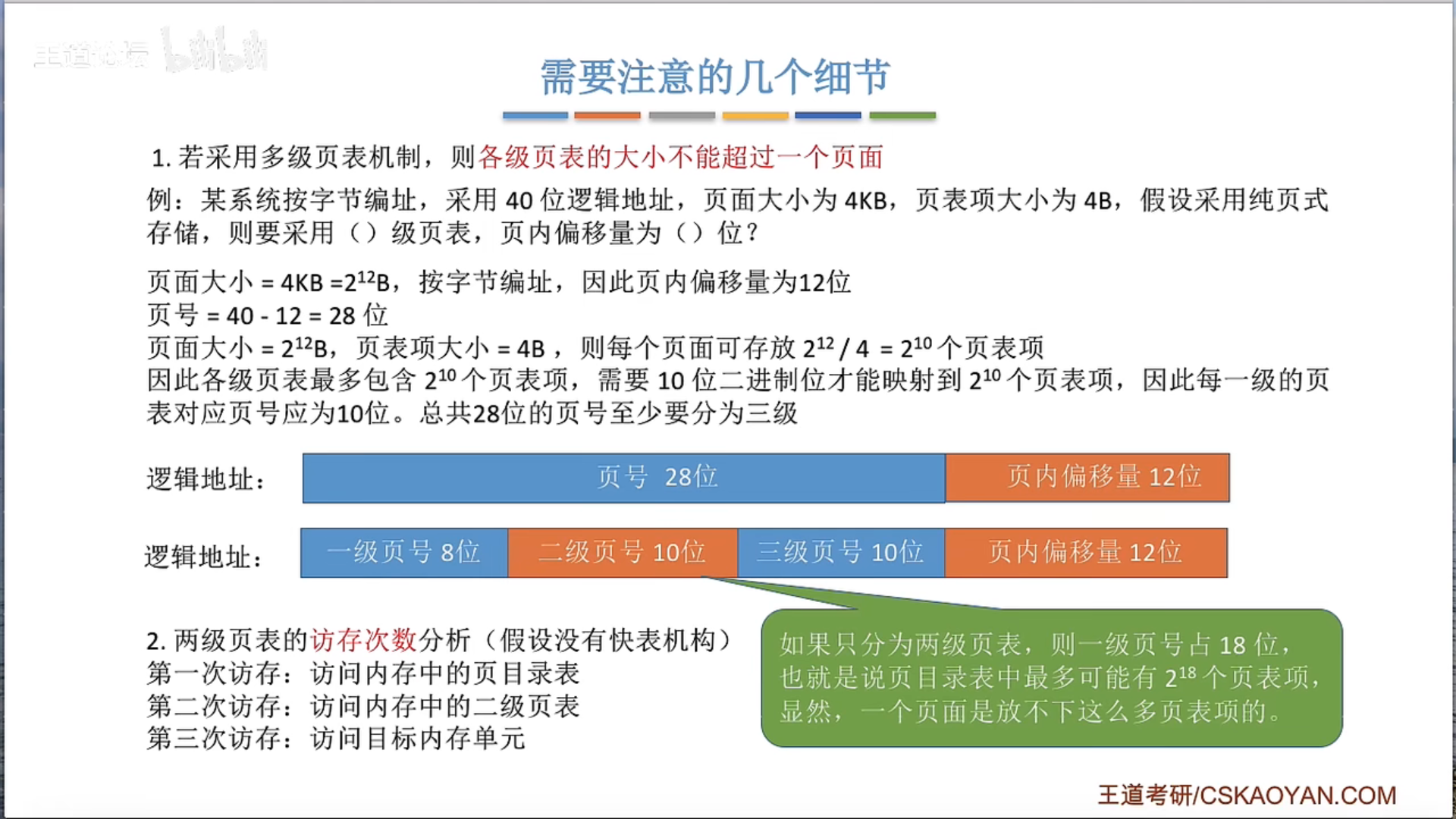
两级页表



3.1.5 基本分段存储管理
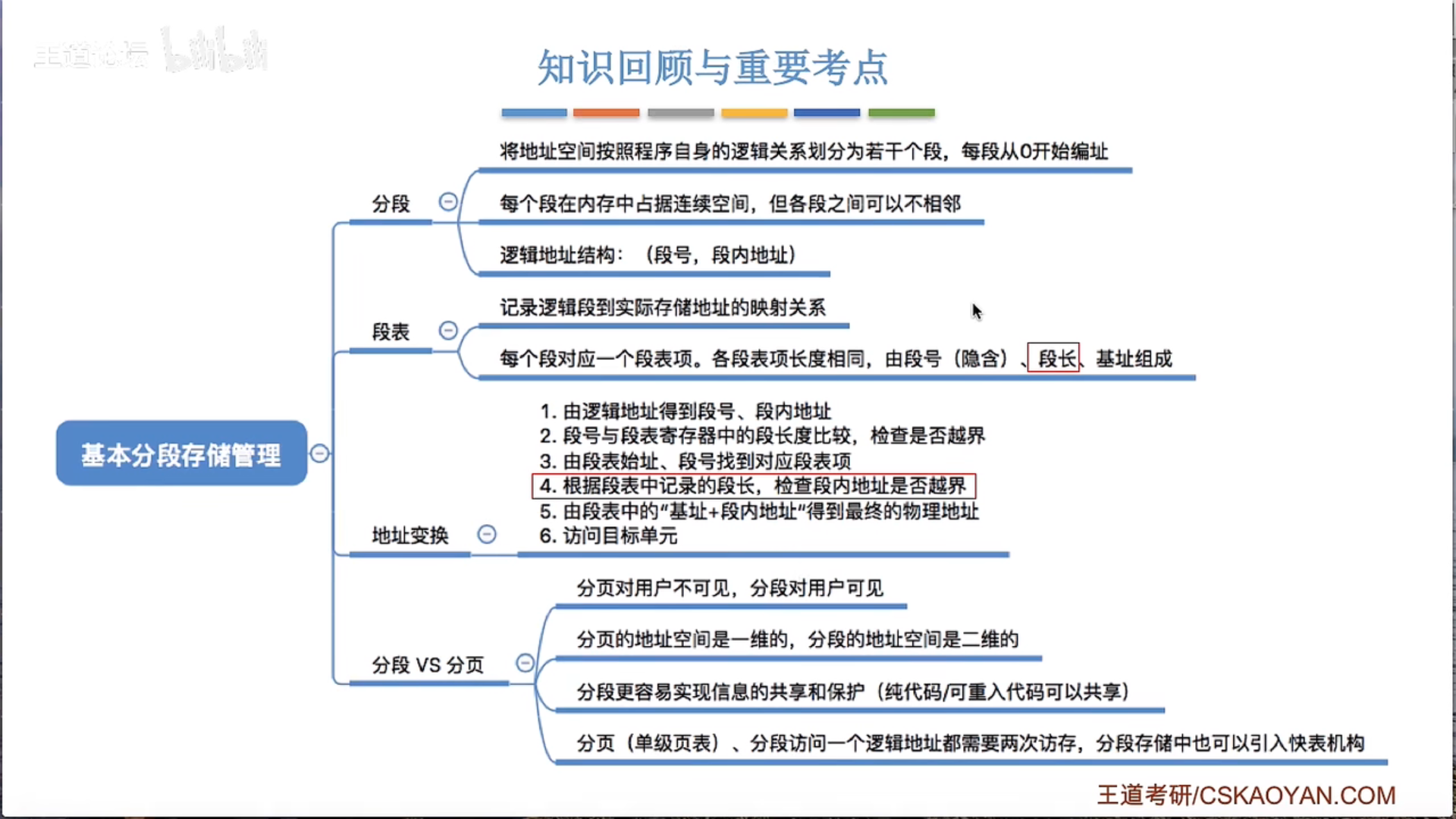
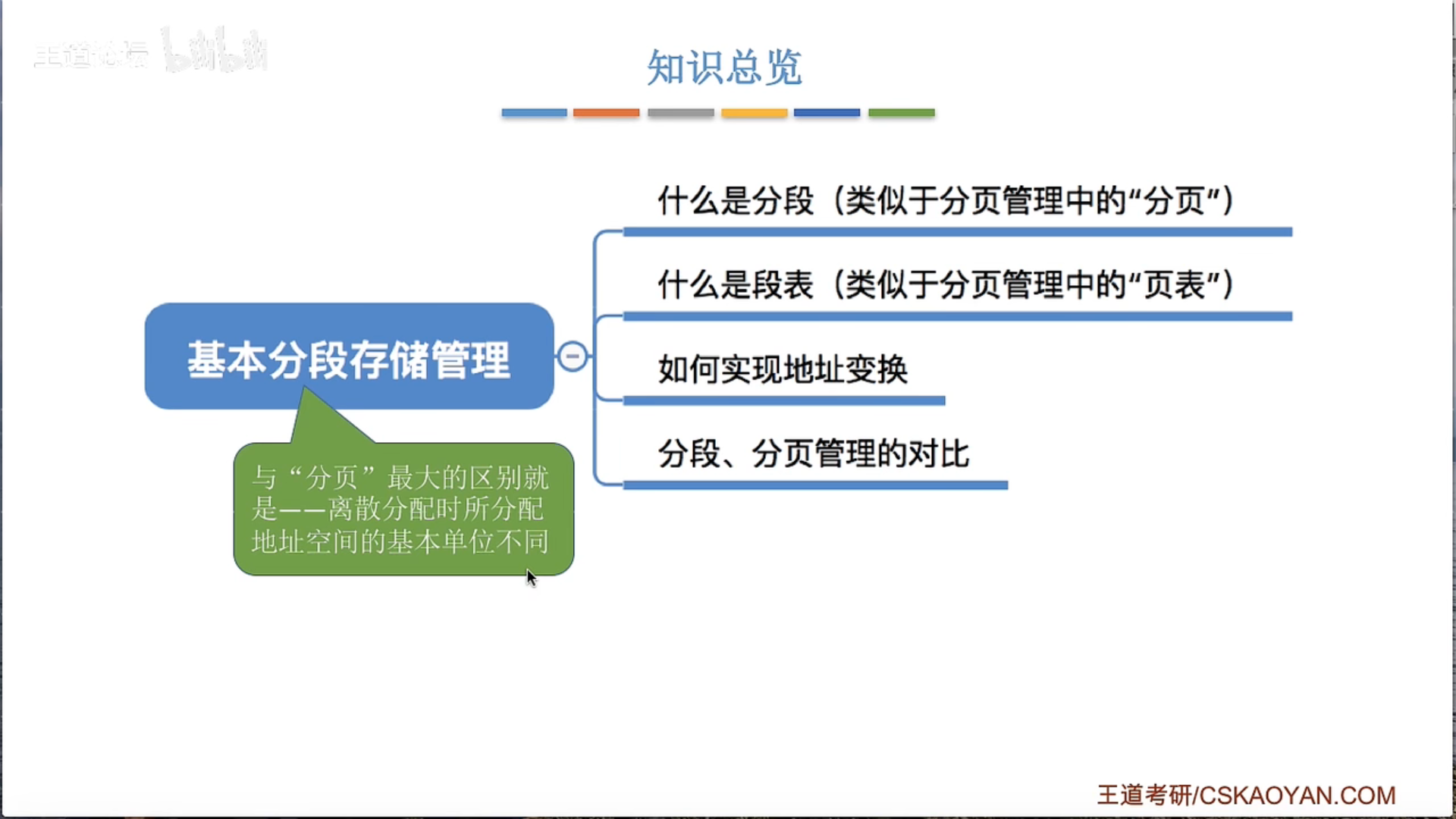

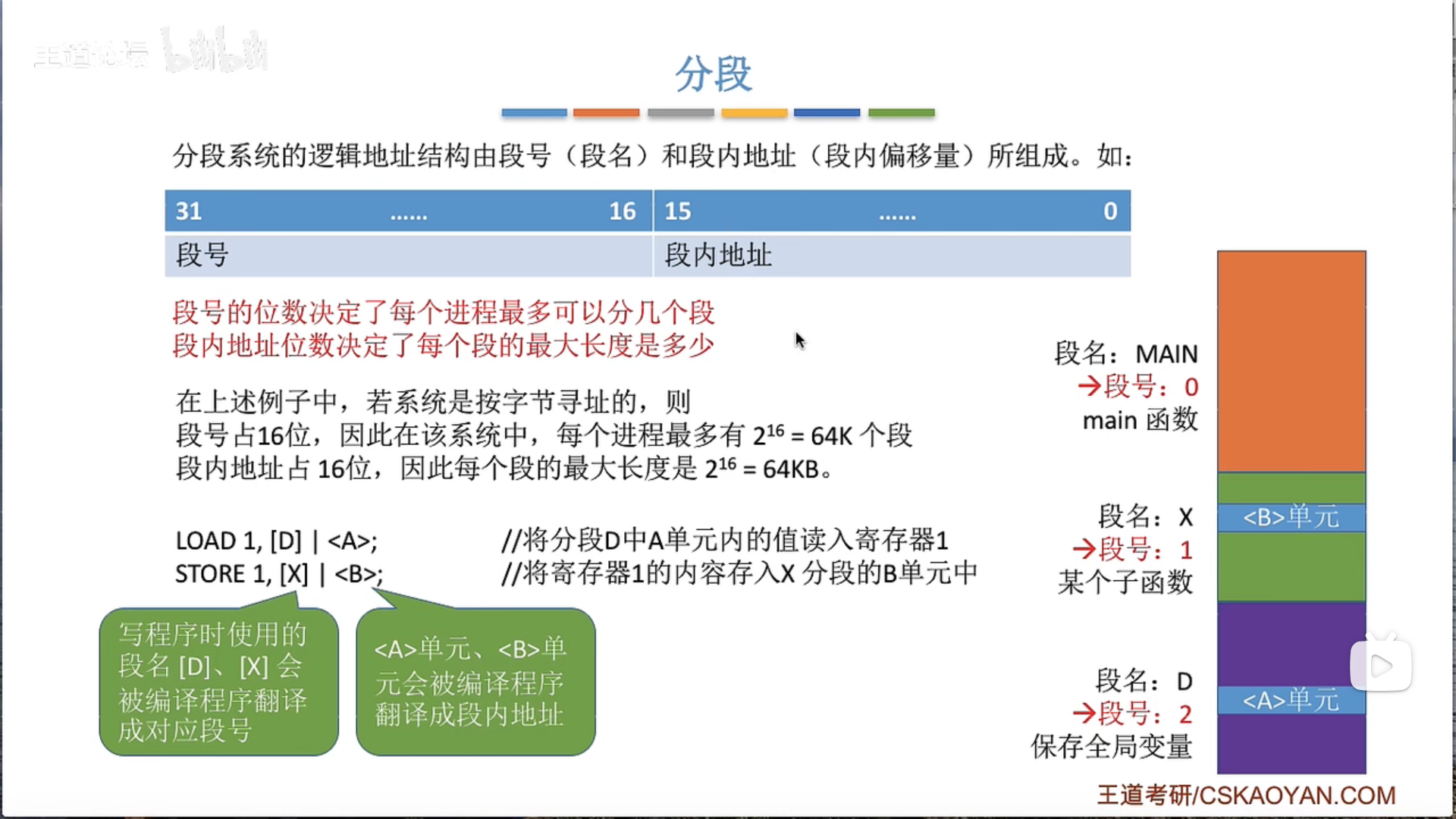
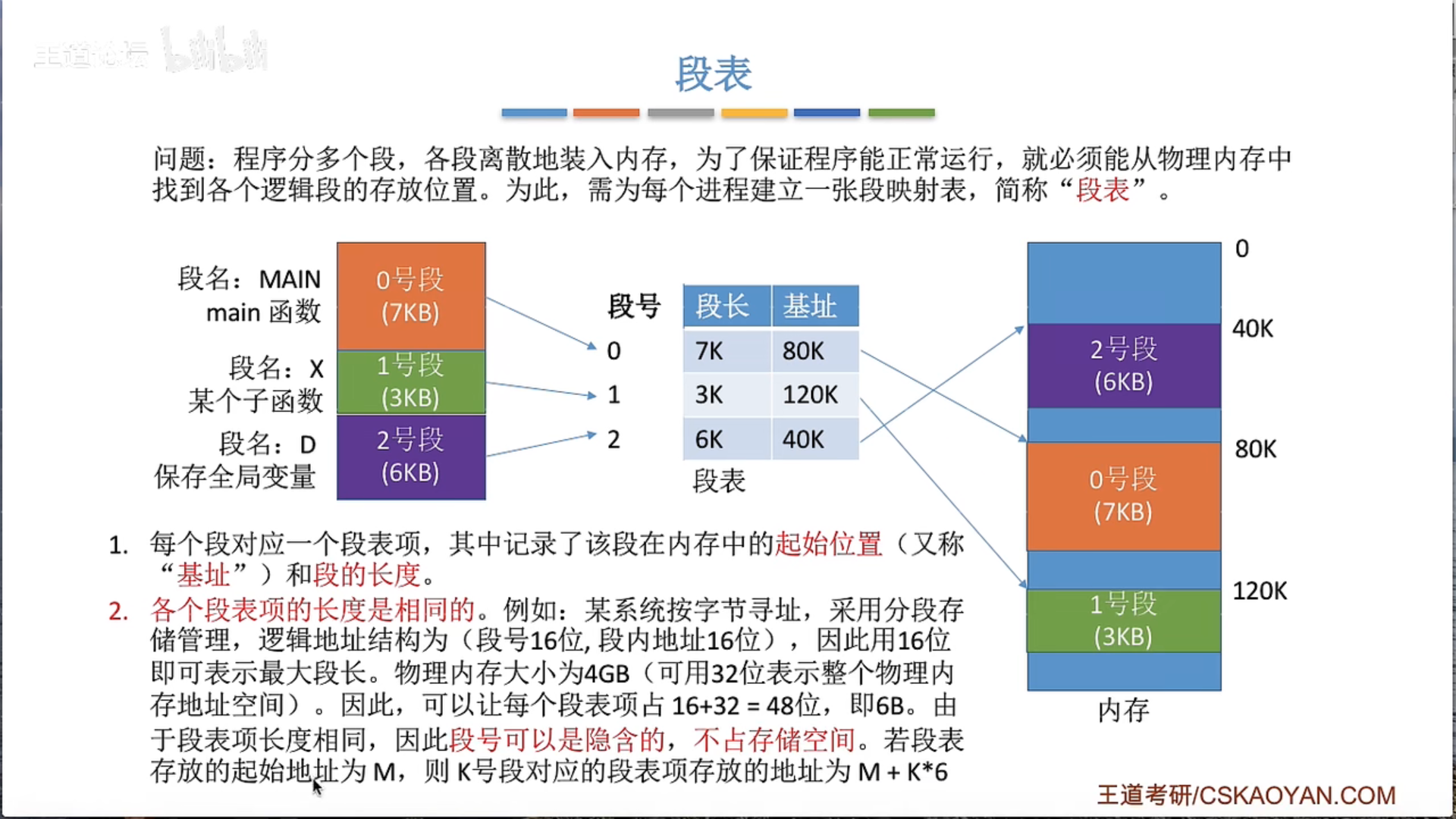
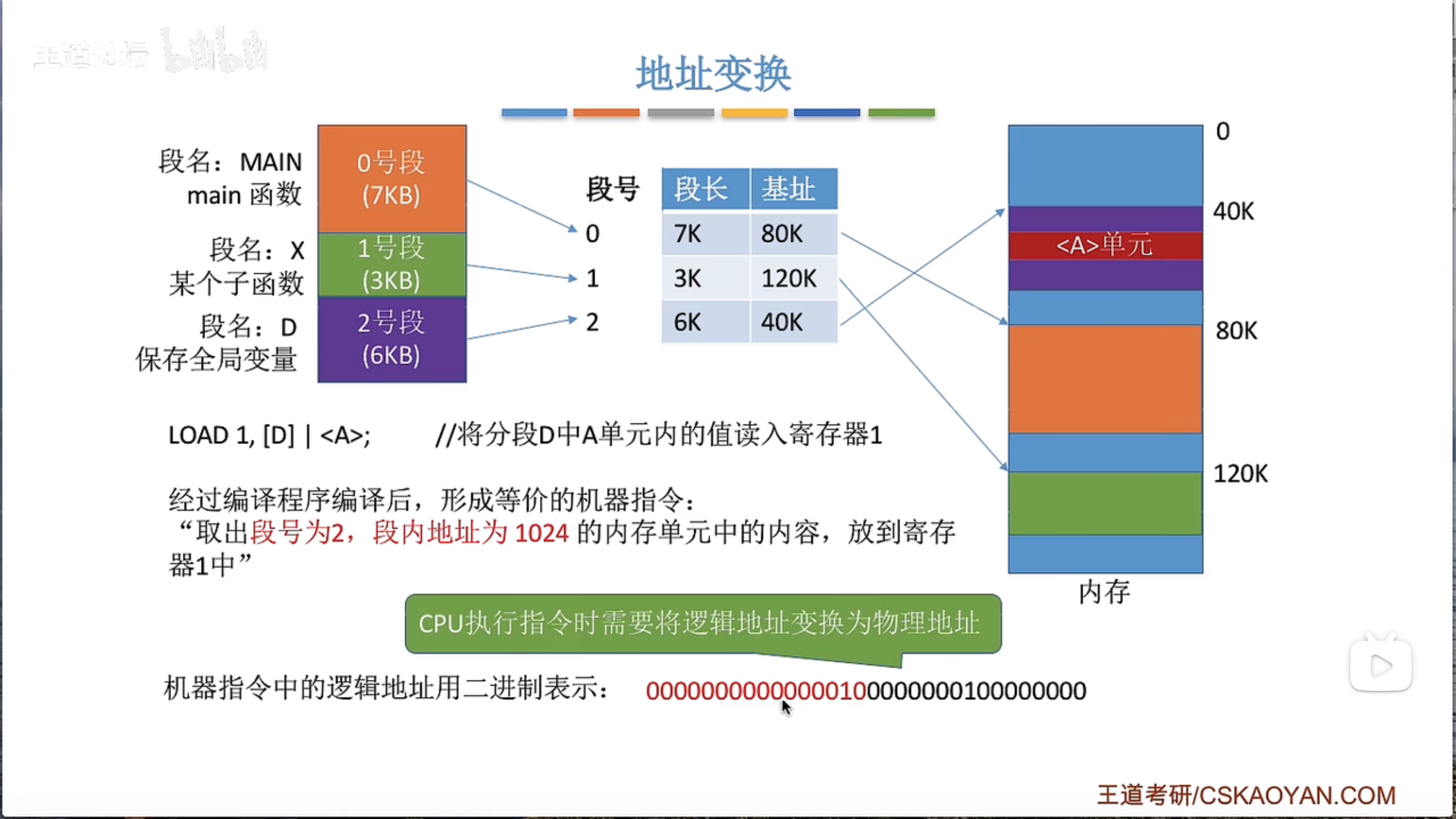
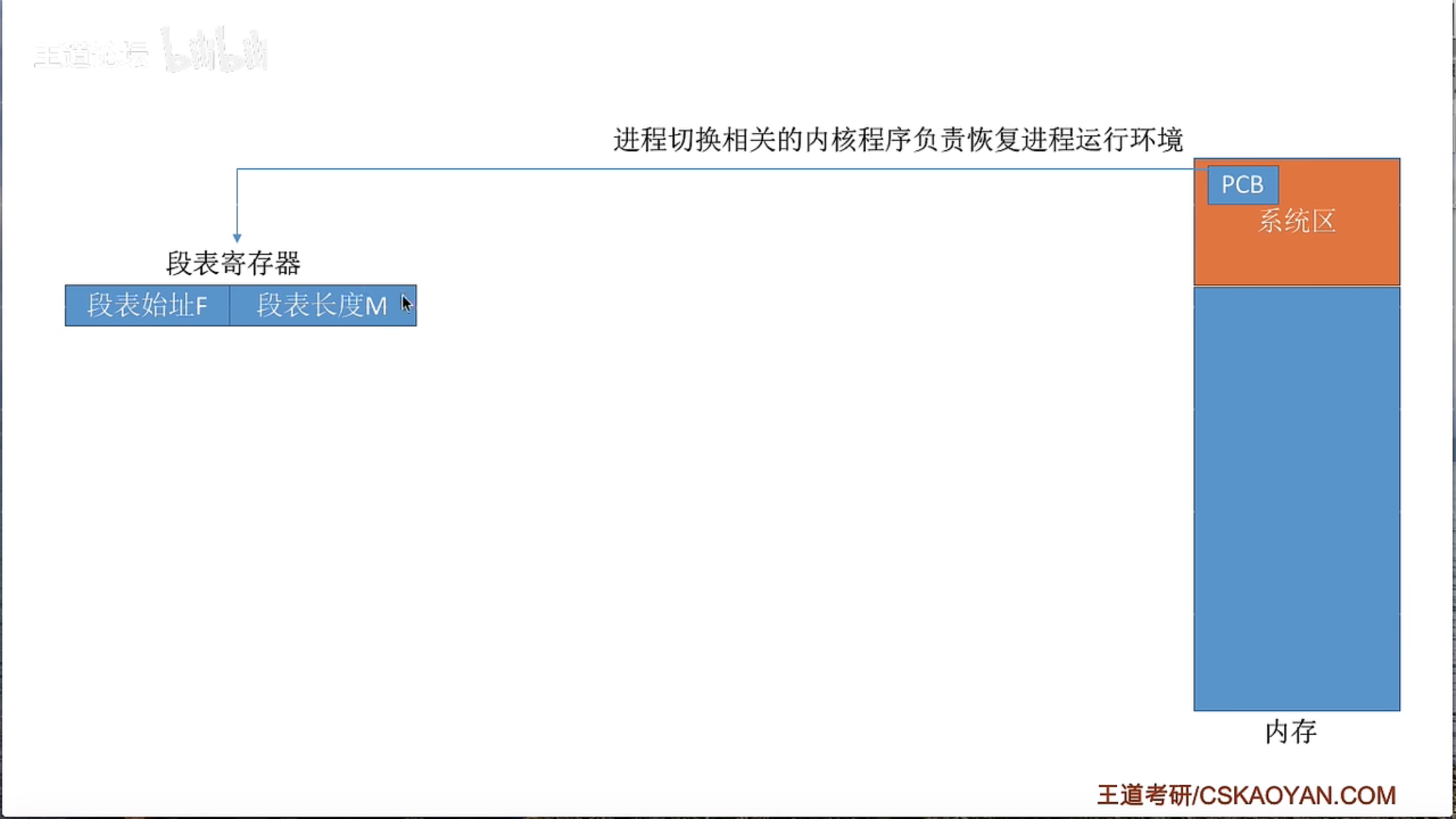
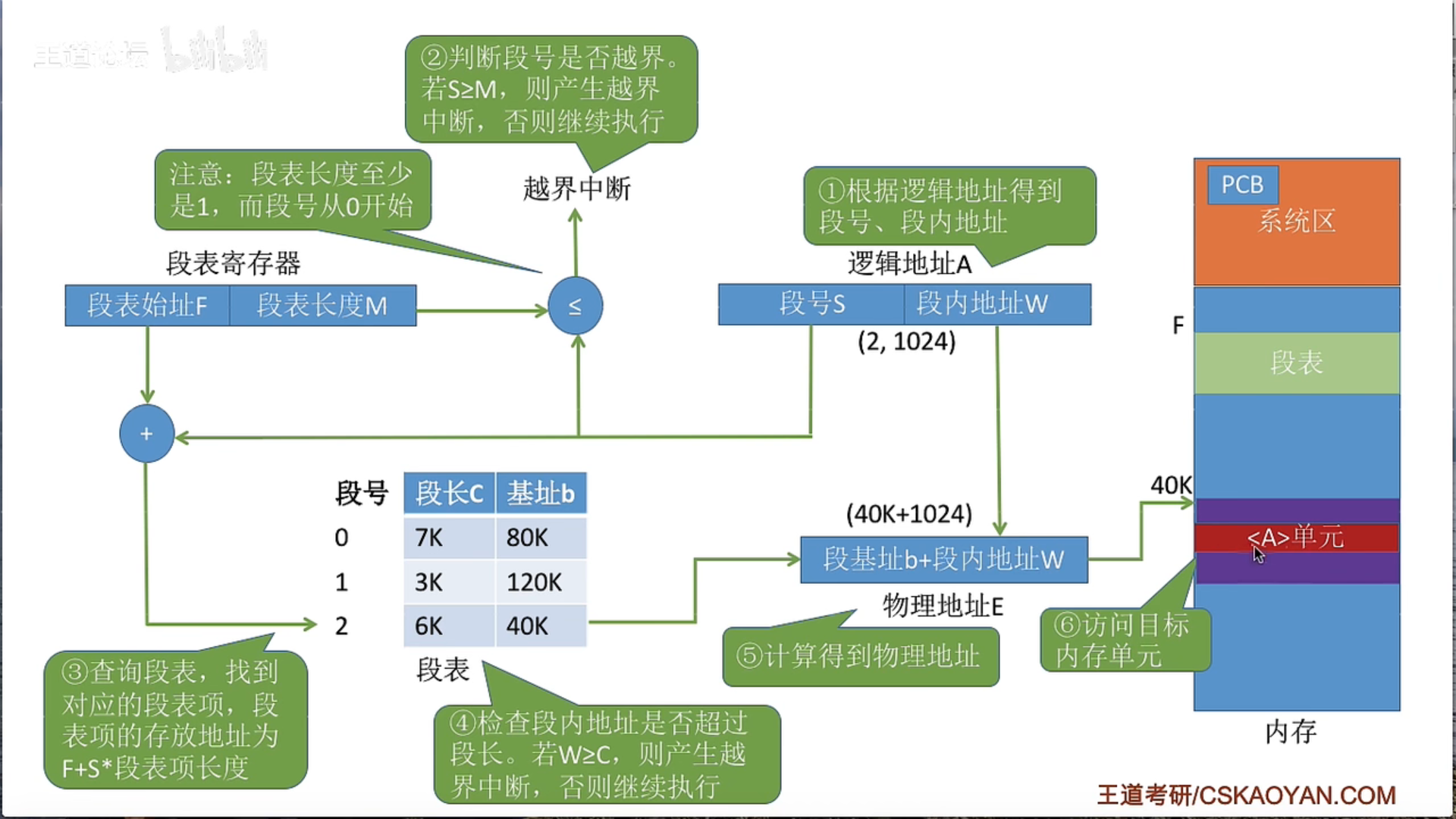



3.1.6 段页式管理
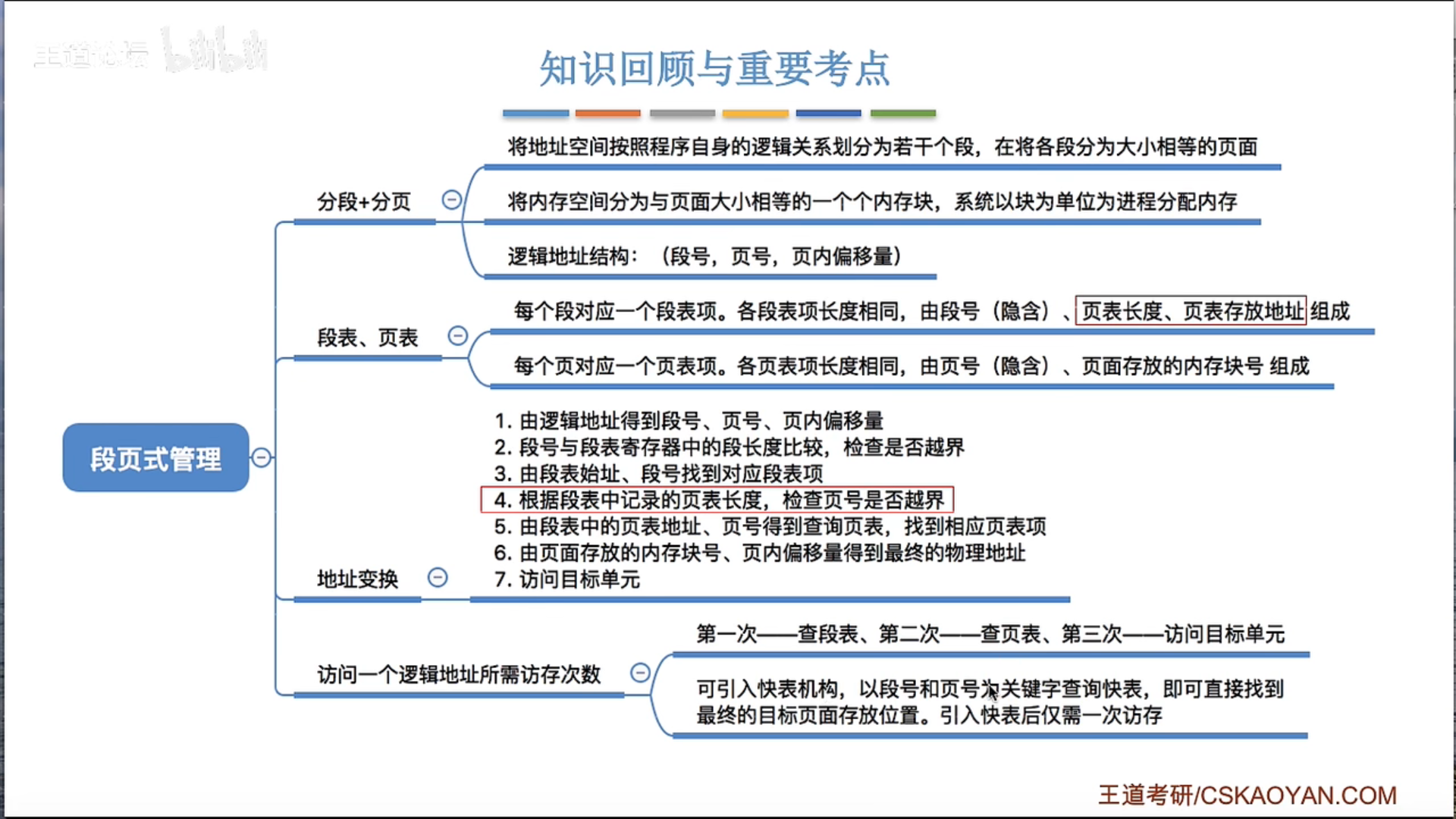
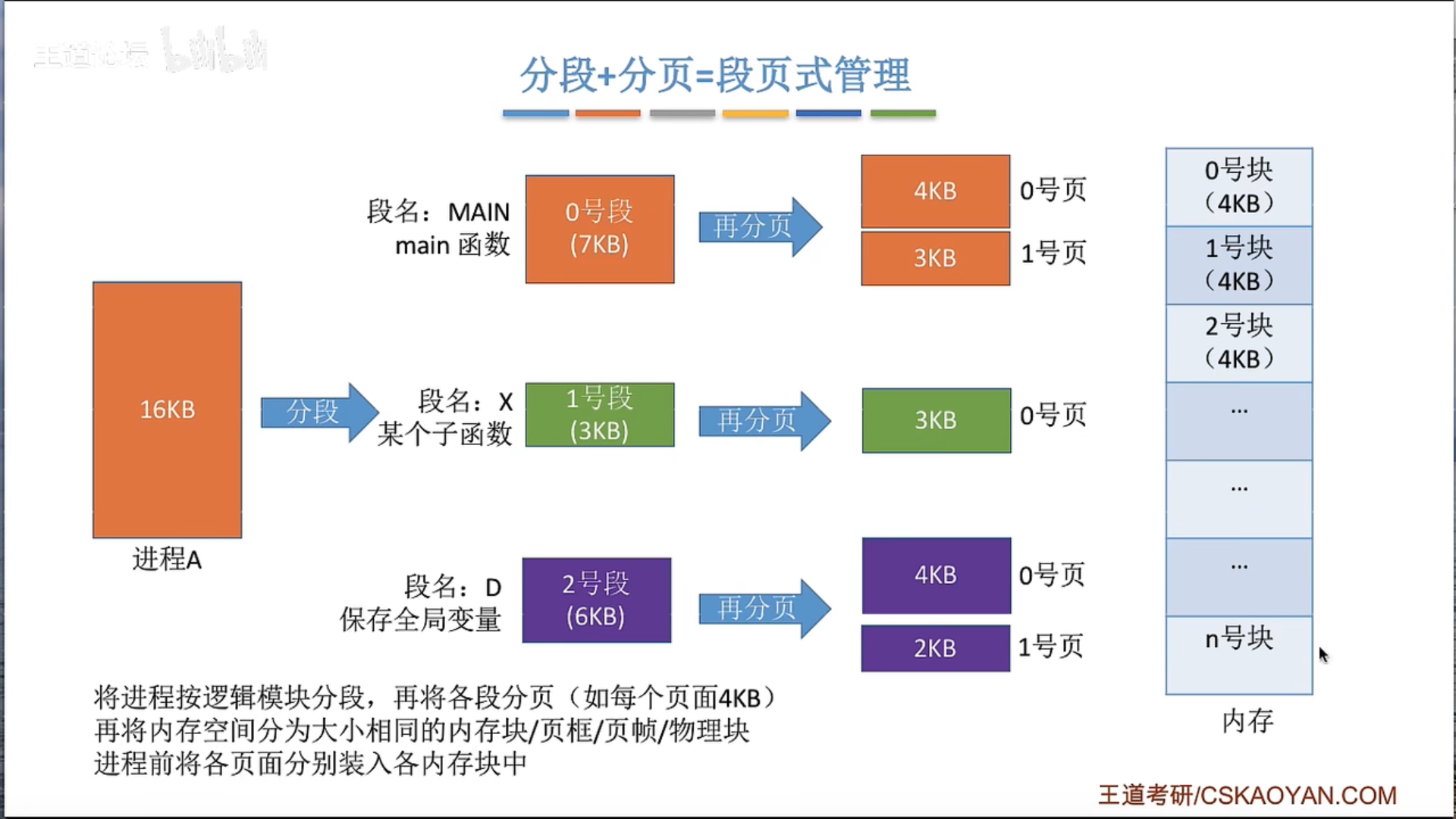

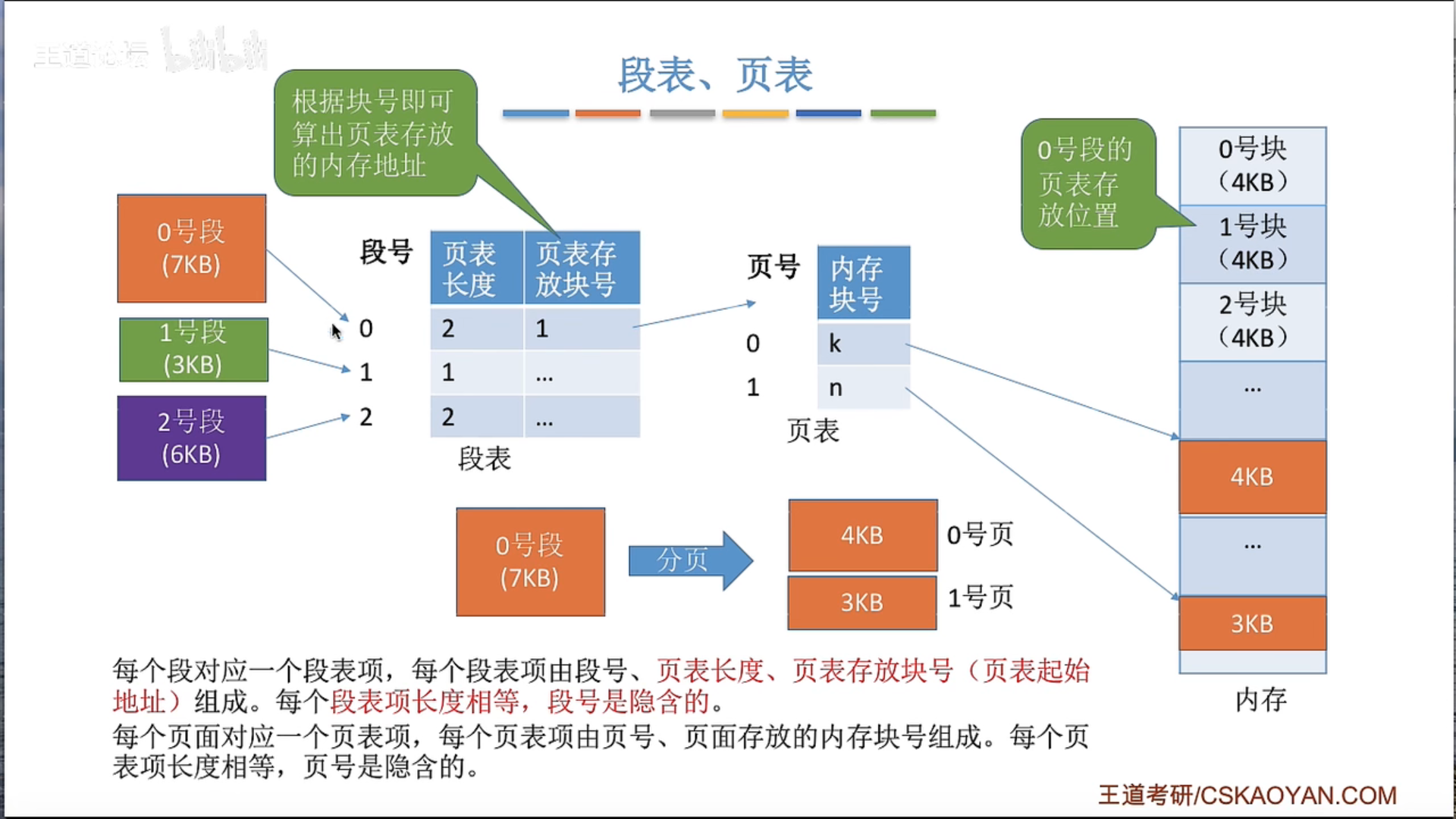

保护码(Protection Code)通常在计算机系统中指的是与内存保护和访问权限有关的一组位(bits)。在许多现代计算机系统,尤其是那些使用分页或段式内存管理的系统中,保护码被用来确定一个程序或进程是否有权访问某一段内存,以及它对这段内存有哪些权限。
保护码通常包含读(R)、写(W)、执行(X)等权限的标识。例如,在一个Unix或Linux系统中,每个内存页的保护码可能包含以下权限:
- 读(R):如果设置了这个位,那么程序可以读取这个页面的内容。
- 写(W):如果设置了这个位,那么程序可以修改这个页面的内容。
- 执行(X):如果设置了这个位,那么程序可以执行这个页面中的代码。
当一个程序试图访问一个内存页时,硬件会检查相应的保护码,以确定该操作是否被允许。如果程序试图进行一个未被允许的操作(例如,试图写入一个只读页面,或者试图执行一个非执行页面的代码),那么硬件会生成一个异常(通常是一个段错误或页错误),操作系统会捕获这个异常,并可能决定终止这个程序。
保护码是计算机系统安全性和可靠性的重要组成部分,它们可以防止程序意外或恶意地修改其它程序或操作系统的代码和数据。
动态增长是什么
"动态增长"通常是指一个程序或数据结构可以根据需要在运行时改变其大小。这在很多计算机科学的领域中都有应用。
例如,在内存管理中,动态增长可能指的是一个程序可以在运行时请求更多的内存,这通常是通过调用如malloc或new等函数实现的。反过来,程序也可以通过调用如free或delete等函数来释放不再需要的内存。操作系统负责满足程序的这些请求,并在必要时将内存重新分配给其他程序。
在数据结构中,动态增长可能指的是一个数组或列表可以在运行时改变其大小。这通常是通过在需要更多空间时重新分配一个更大的内存块,并将旧的数据复制到新的内存块中实现的。反过来,如果数据结构中的元素被删除,它也可能会缩小其大小以节省内存。
动态增长是现代编程语言和操作系统的一个重要特性,它使得程序可以更有效地使用内存,并可以更容易地处理变化的数据量。
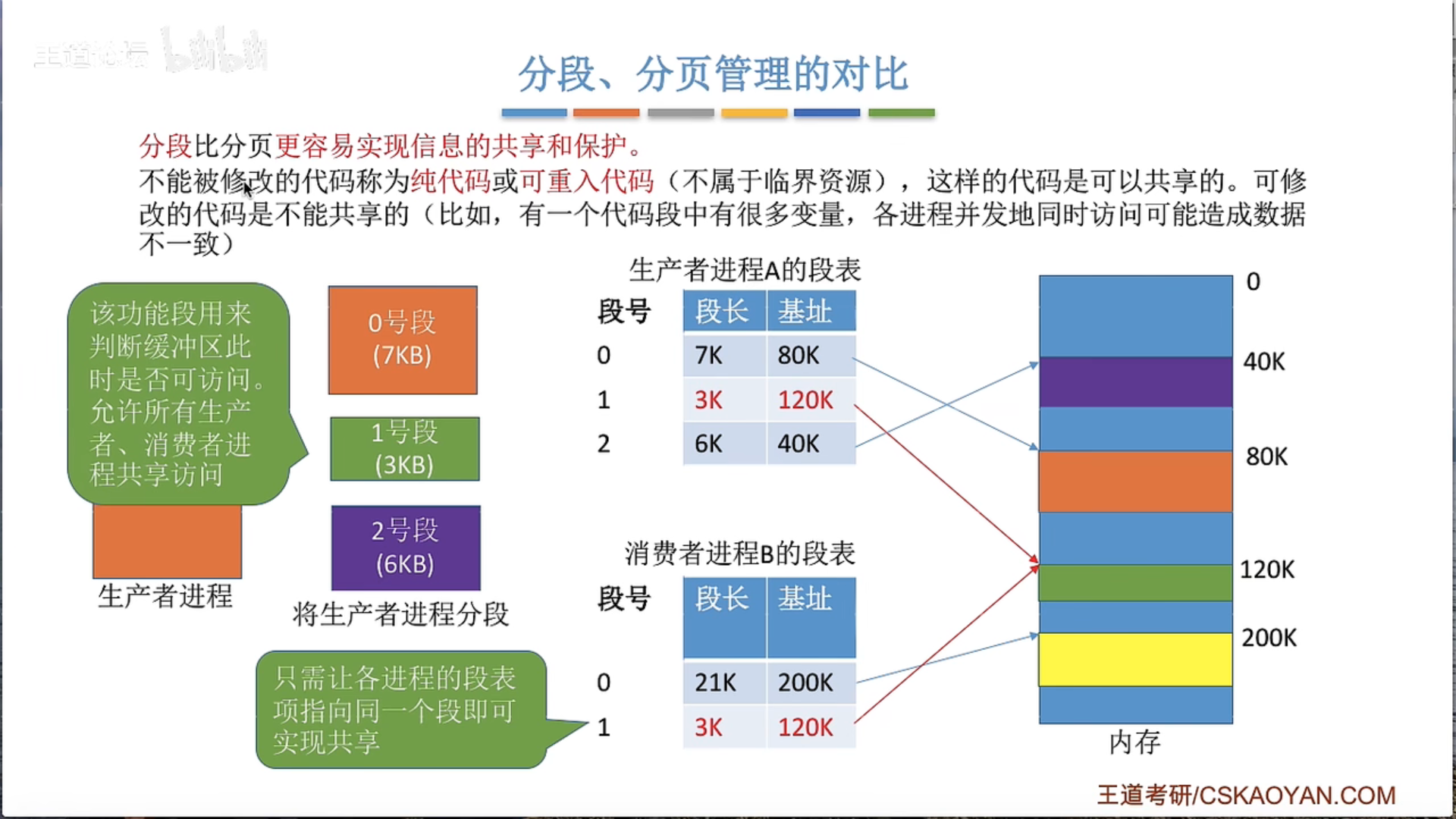
分段比分页管理方式更易于动态增长吗
分段和分页是两种不同的内存管理技术,它们各有优点和缺点。关于哪种方法更适合动态增长,可能取决于具体的应用场景。
分段:分段内存管理把程序划分为多个逻辑段,比如代码段、数据段、堆段、栈段等。每个段都有其独立的起始地址和长度,可以独立地加载和卸载。分段很自然地支持了动态增长,特别是对于堆和栈这样的动态数据结构。例如,当程序需要更多的堆空间时,可以简单地增加堆段的长度。同样,当函数调用产生了新的栈帧时,可以增加栈段的长度。但是,分段管理也可能导致内存碎片,因为不同段的大小可能会有很大的差异。
分页:分页内存管理把内存划分为固定大小的页,每一页都有一个唯一的物理地址。分页使得内存的使用更加灵活,可以有效地处理小的内存请求。而且,由于所有的页都是同样大小的,所以分页几乎消除了内存碎片的问题。然而,分页对于动态增长的支持不如分段直观。例如,当一个程序需要更多的内存时,需要申请新的页,并可能需要重新组织页表来映射这些新的页。
总的来说,分段可能更直观地支持动态增长,因为它允许每个段有独立的长度。然而,分页提供了更灵活和高效的内存使用,几乎消除了内存碎片,尽管它对动态增长的支持可能需要更多的管理开销。许多现代操作系统,包括Linux和Windows,实际上同时使用了分段和分页,以充分利用这两种方法的优点。
3.2 虚拟内存
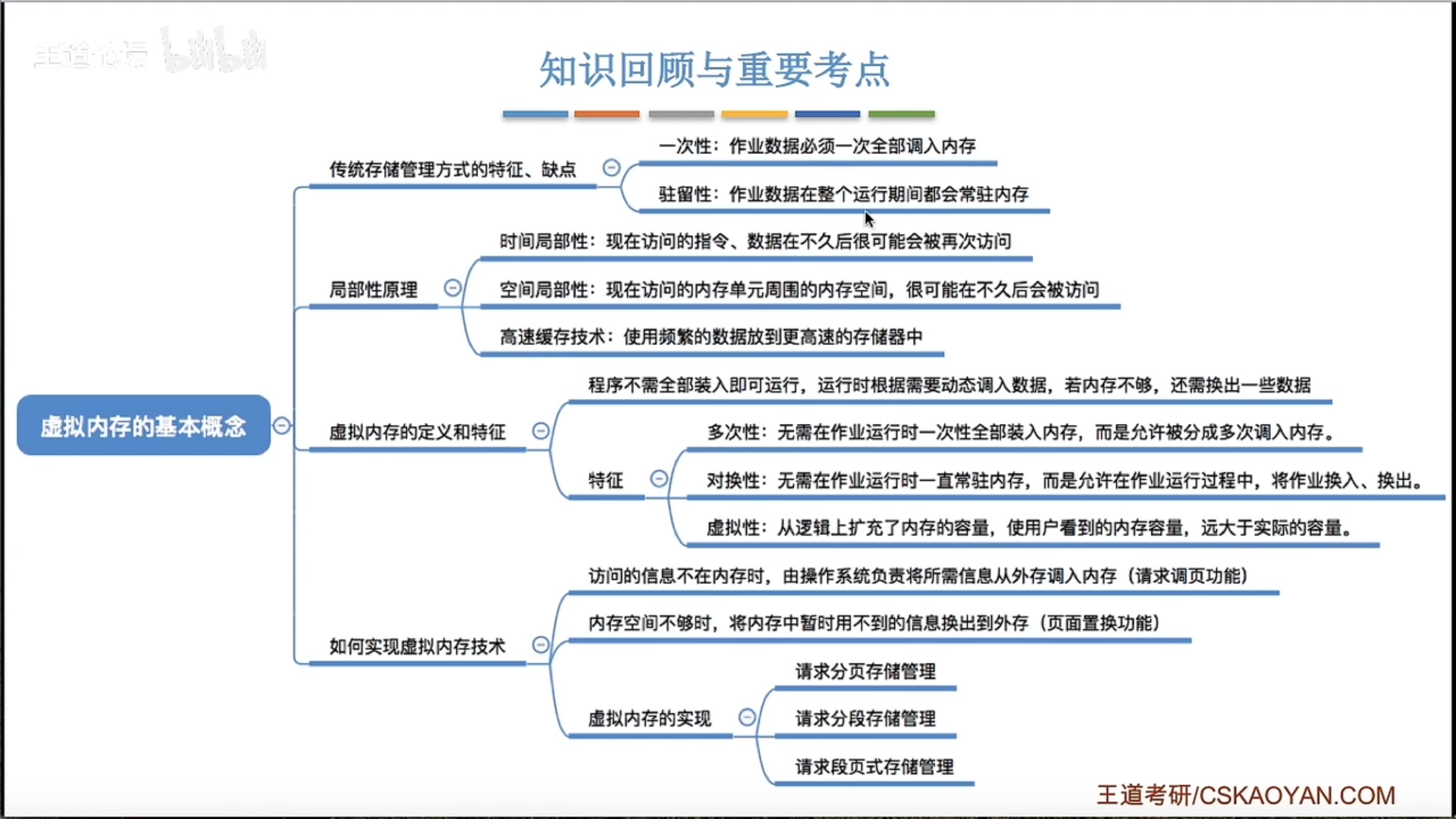
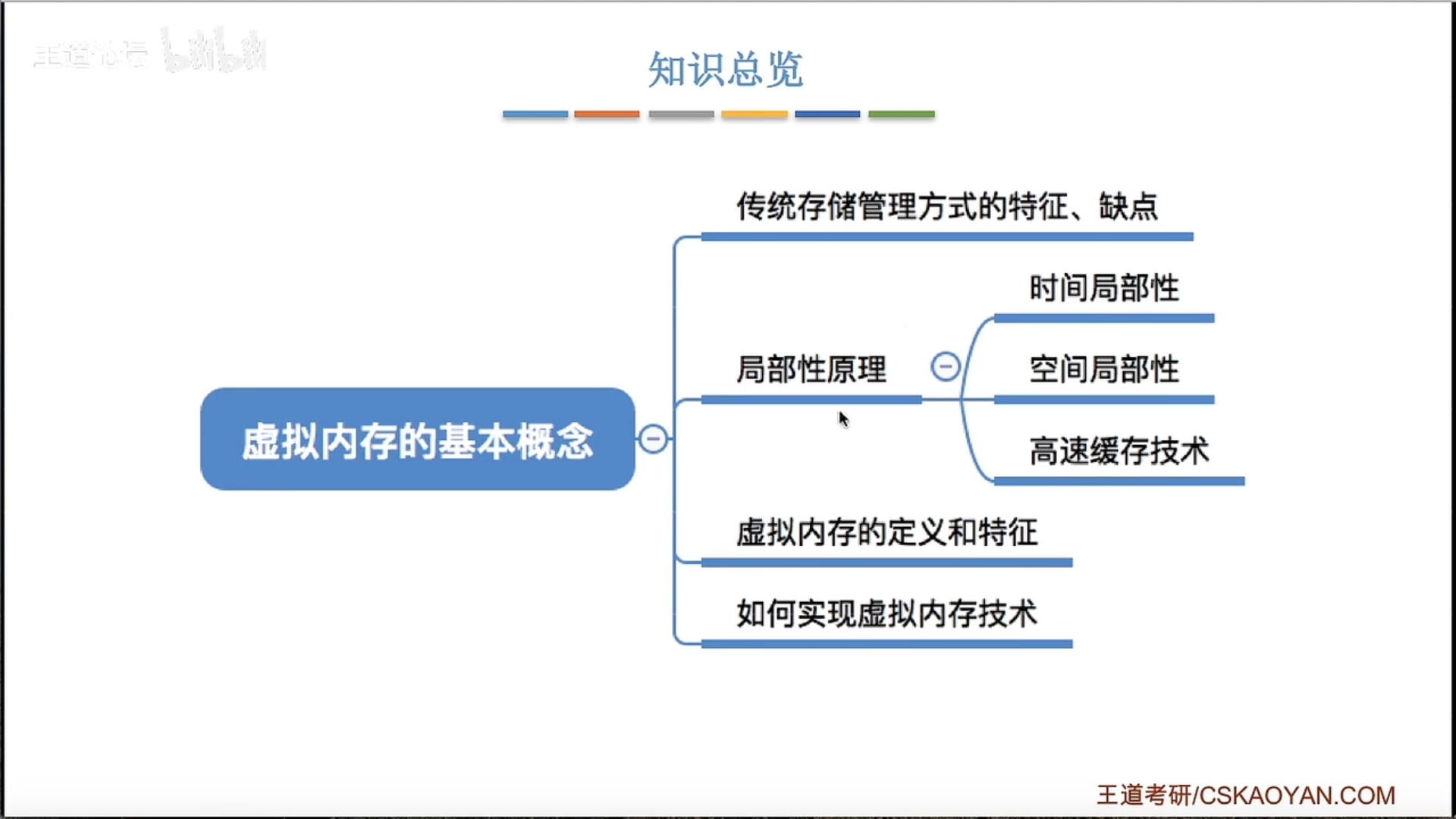
3.2.1 虚拟内存的基本概念

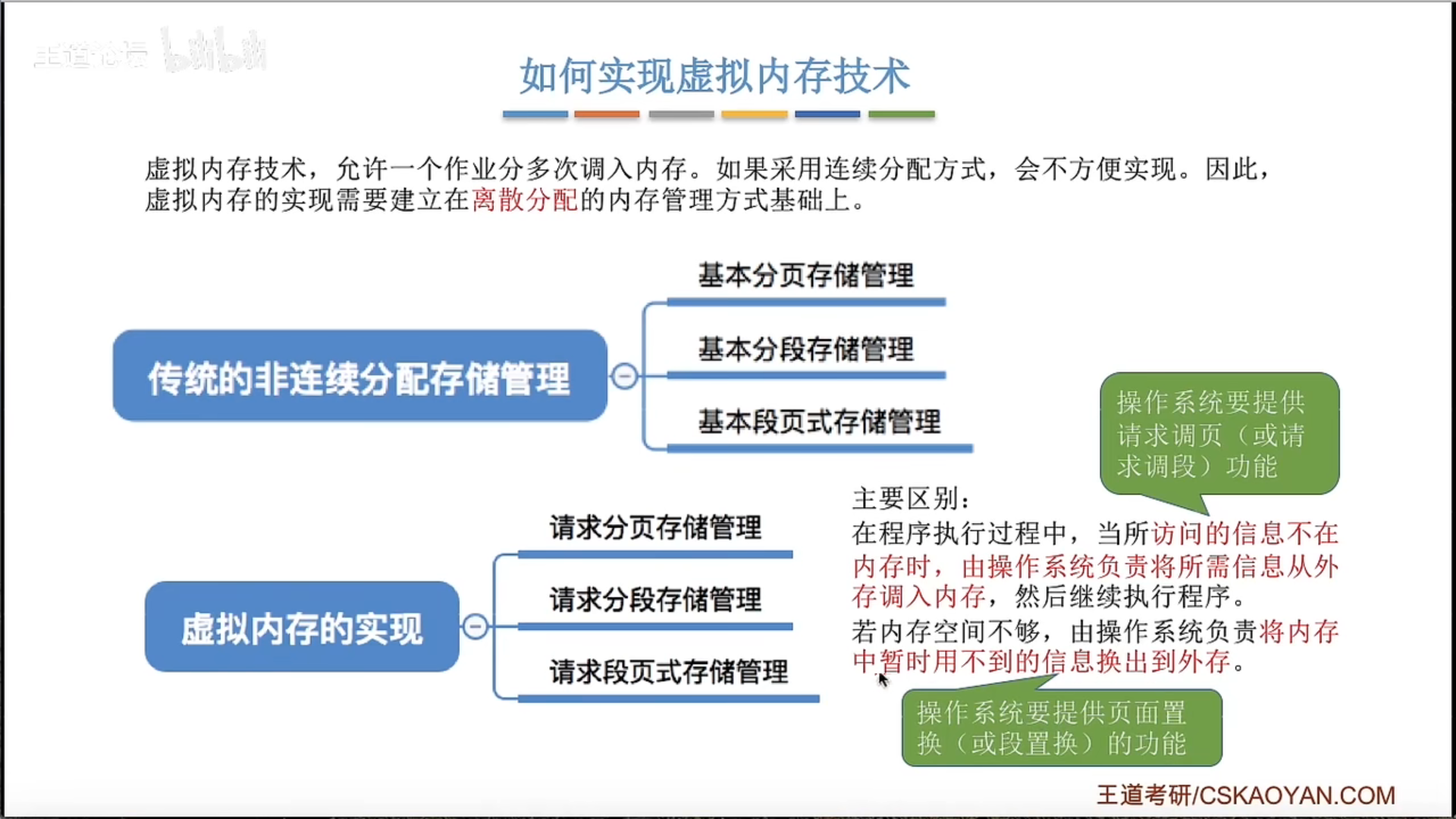
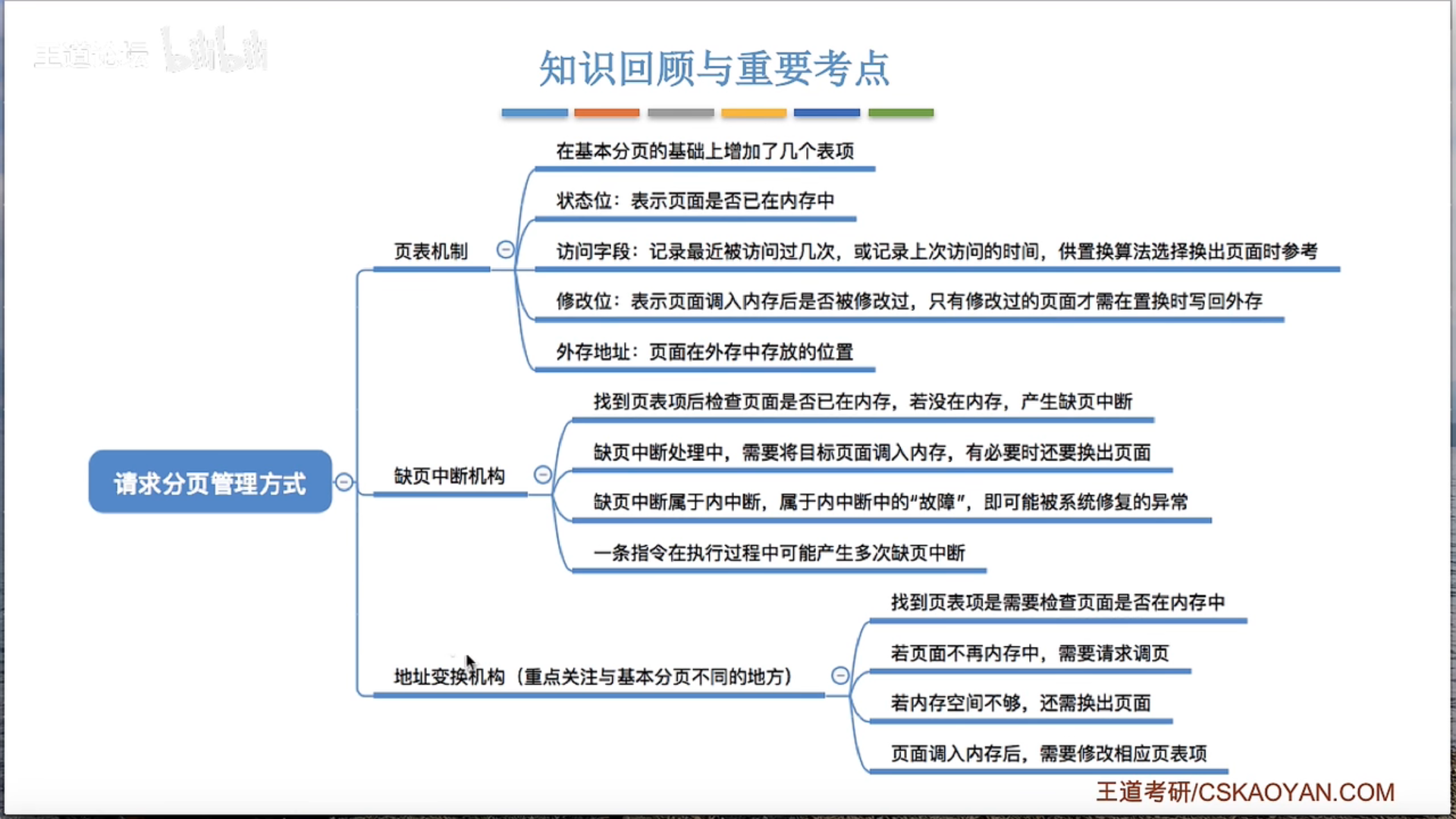
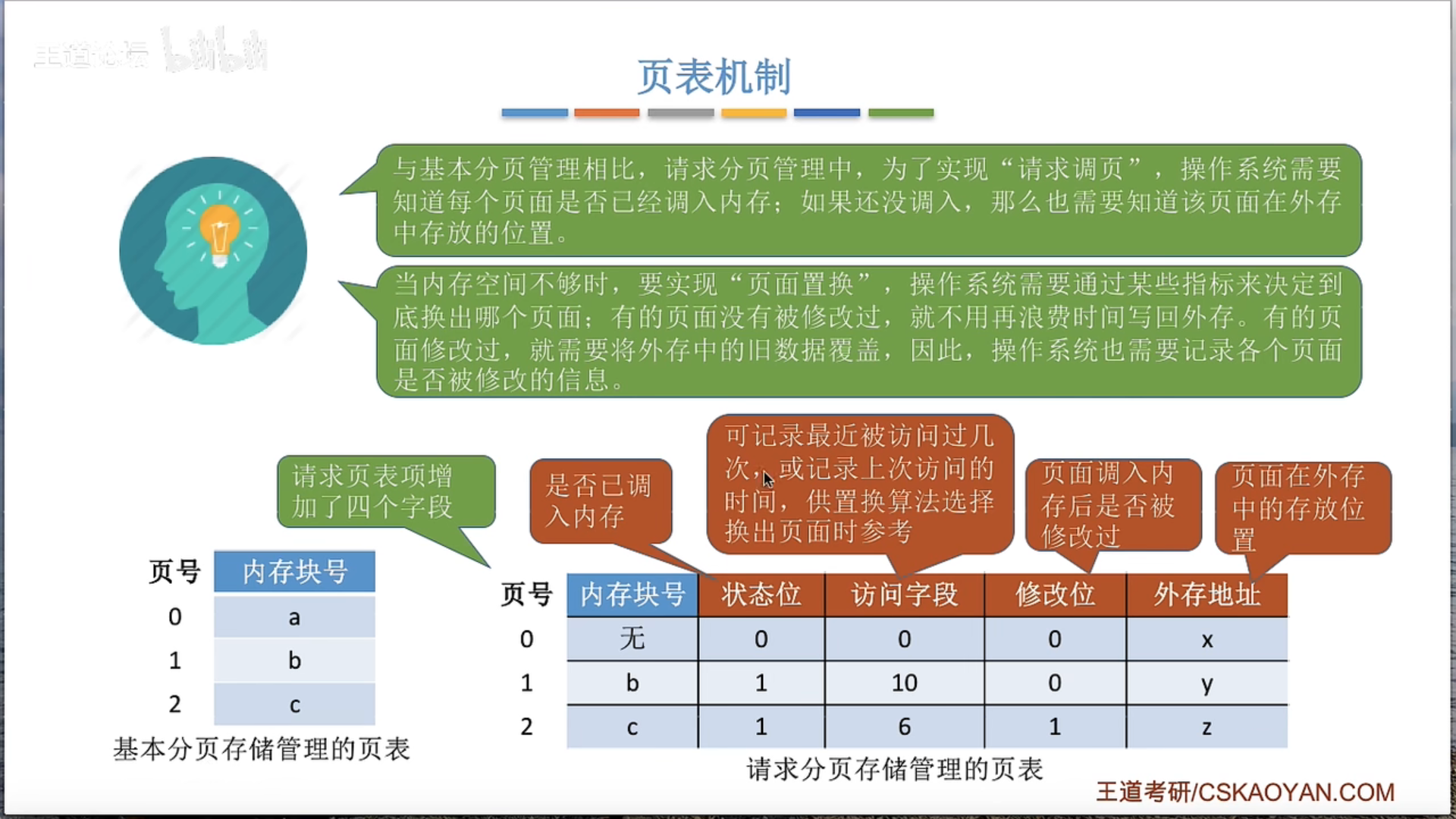
3.2.2 请求分页管理方式

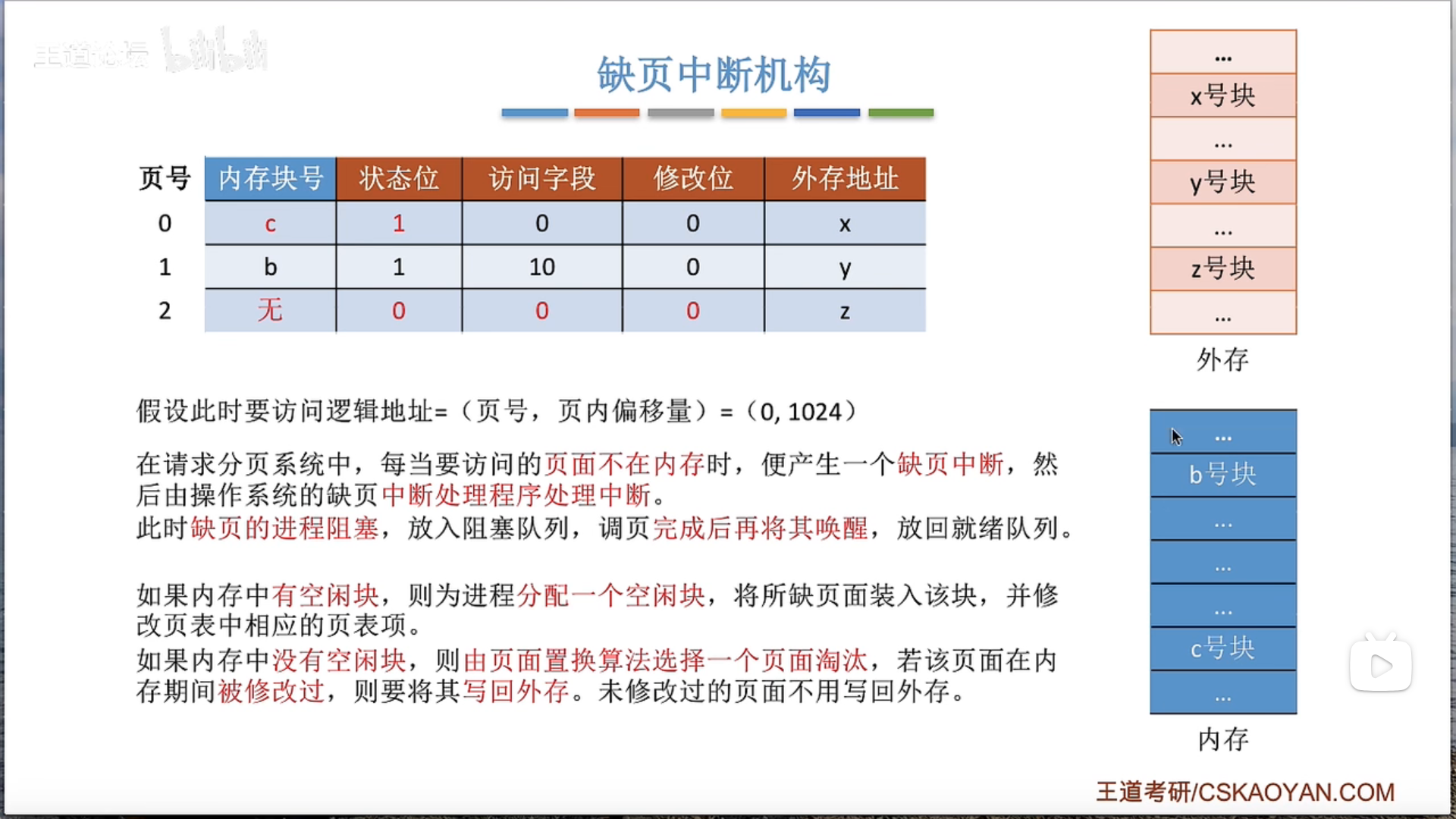



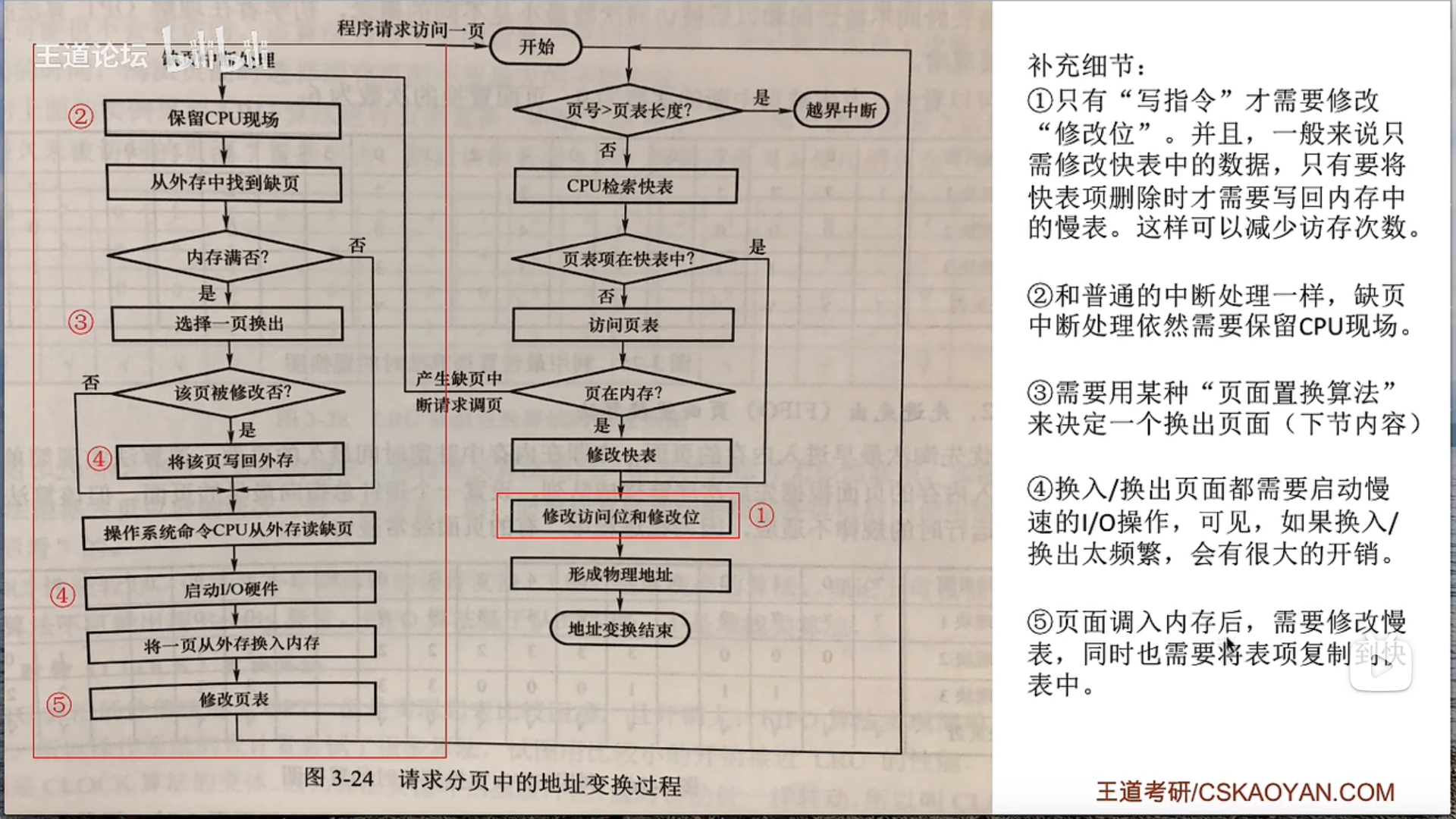

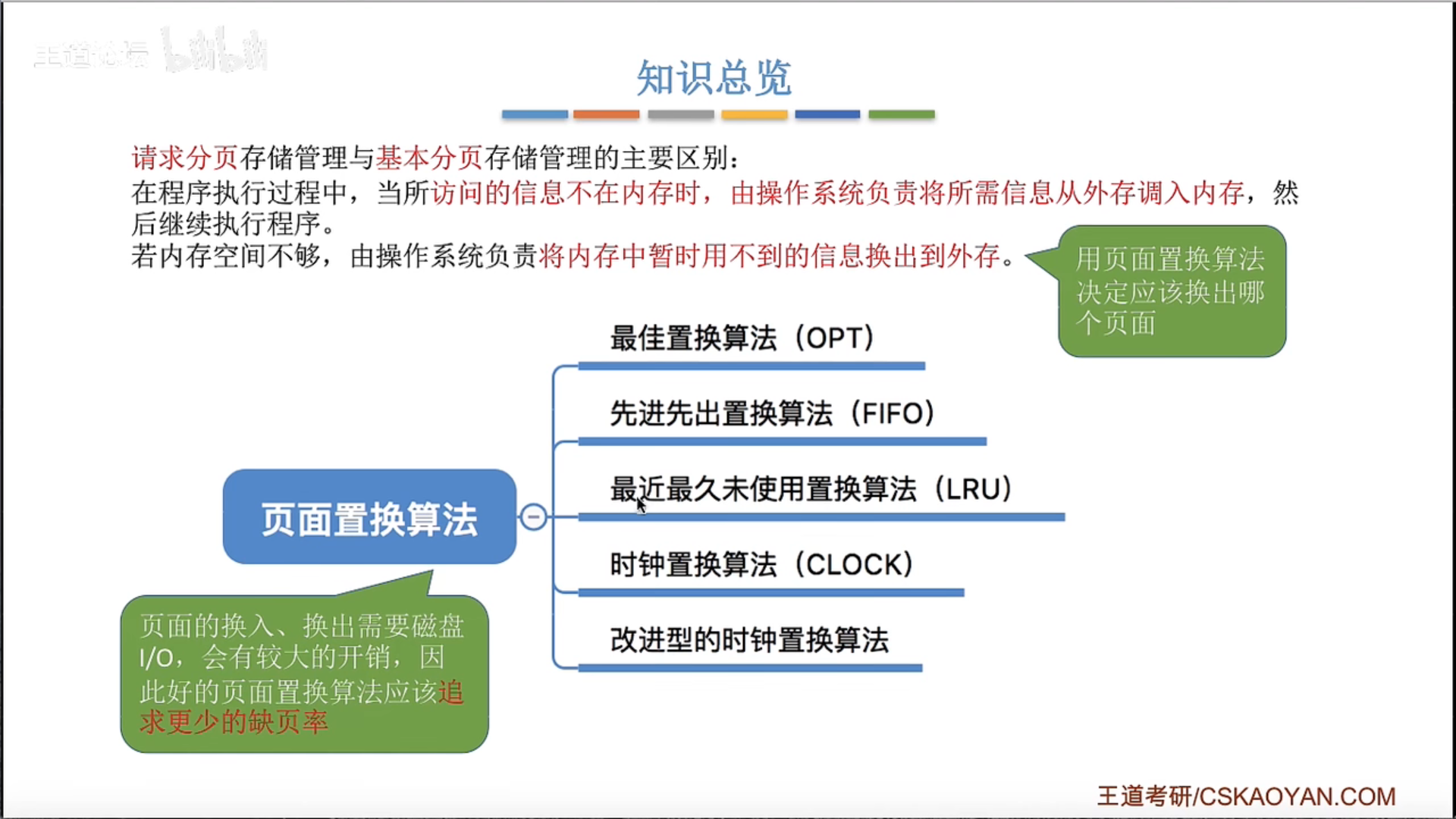
3.2.4 页面置换算法
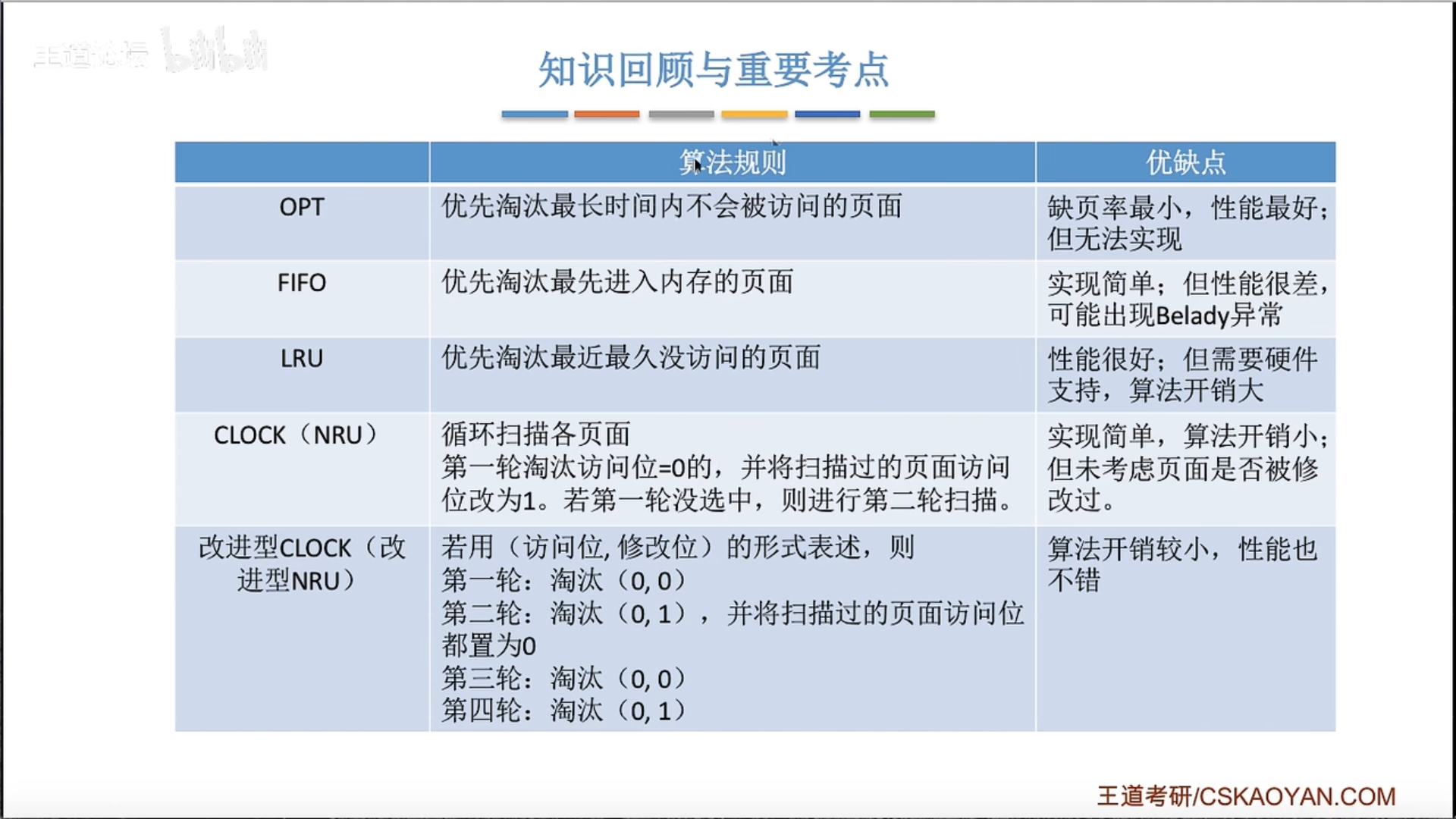
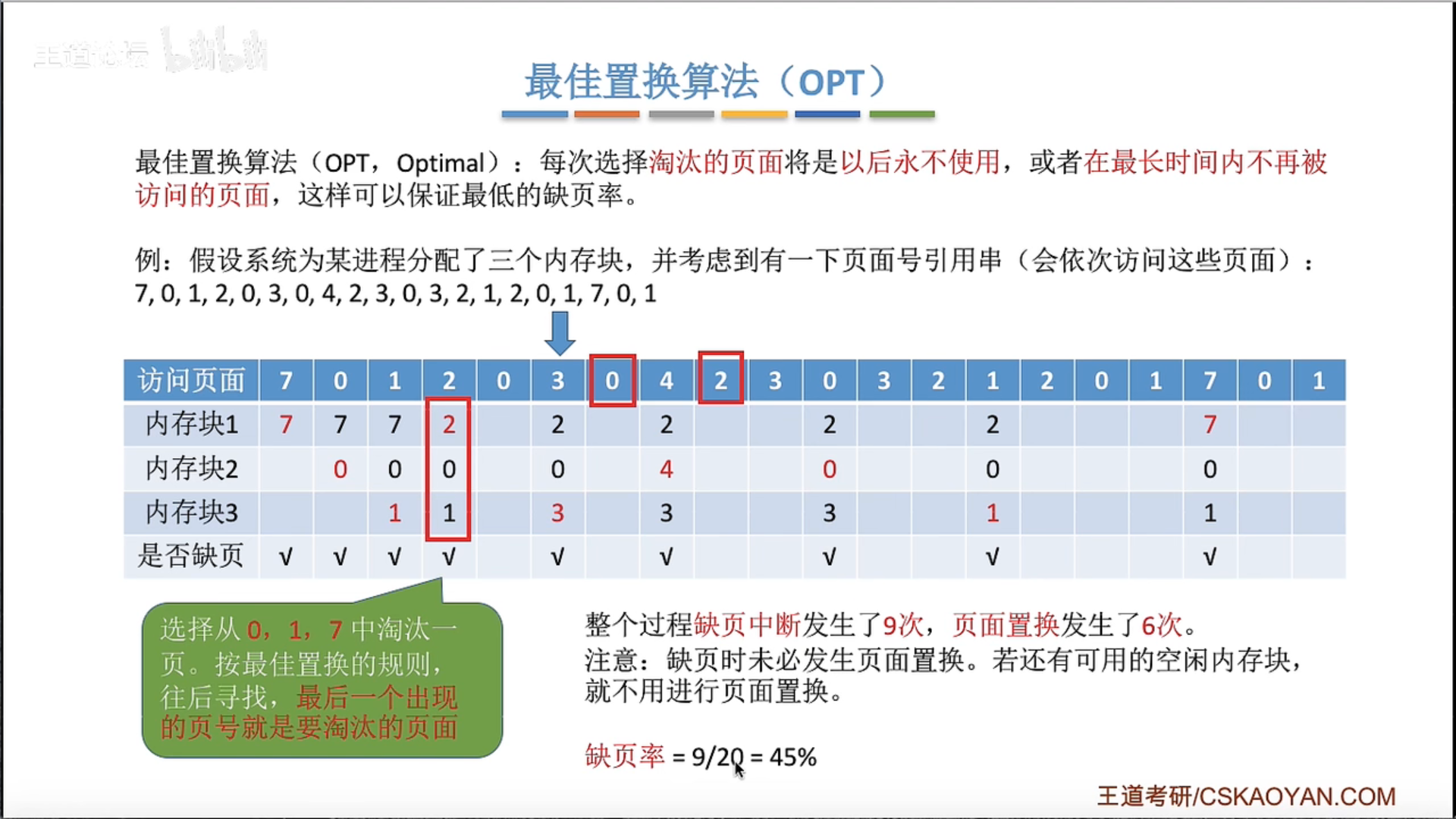

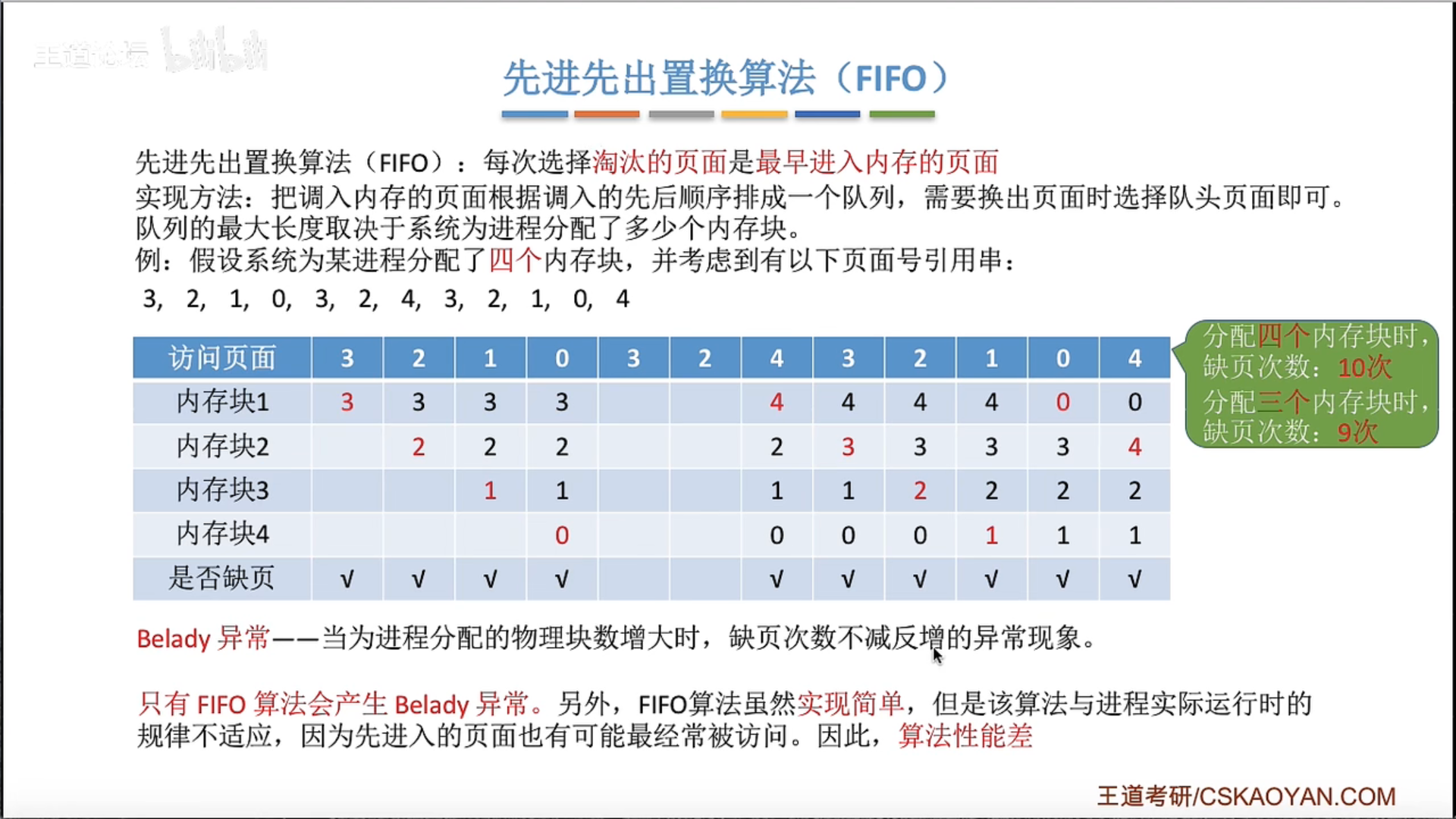
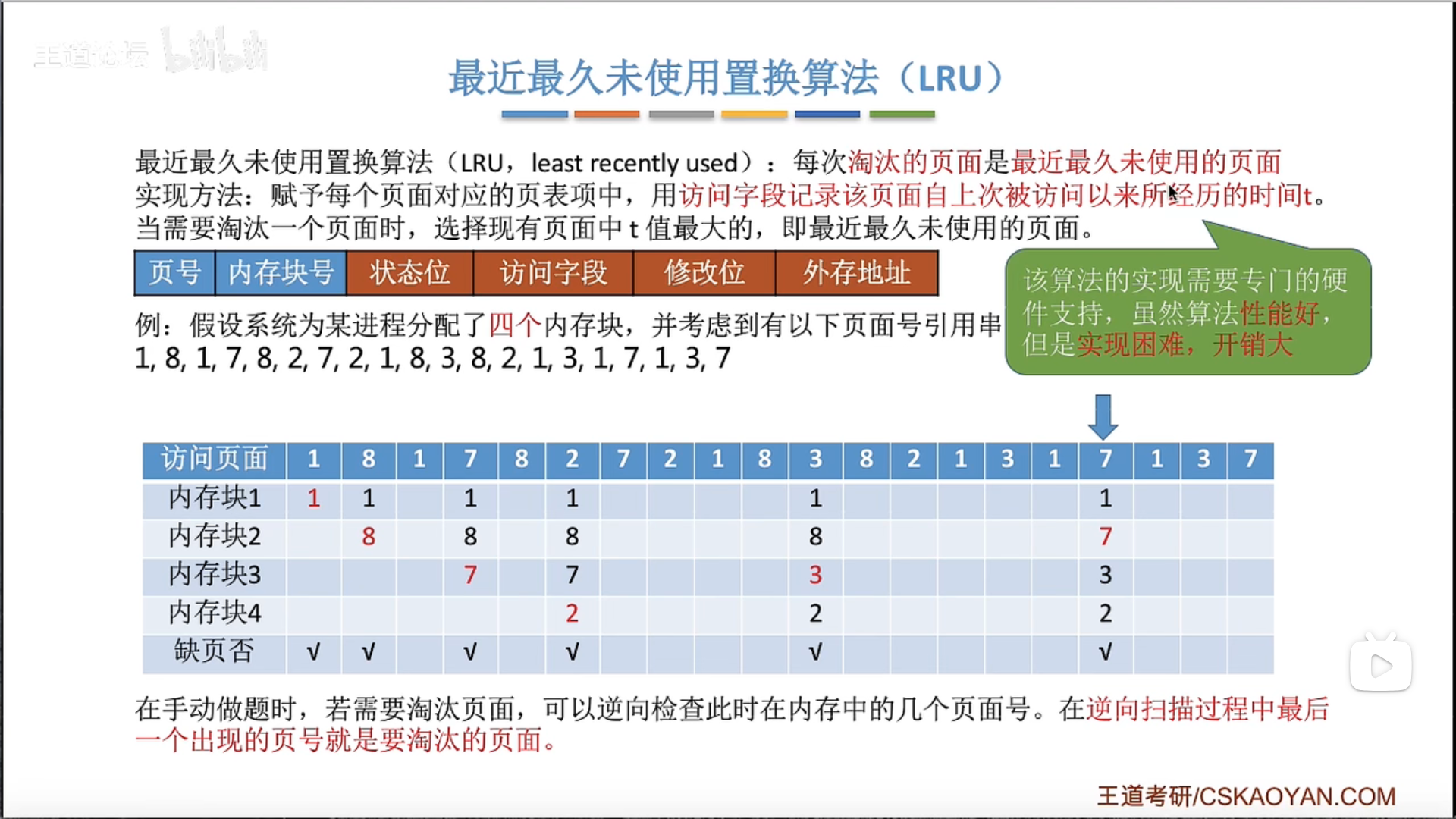
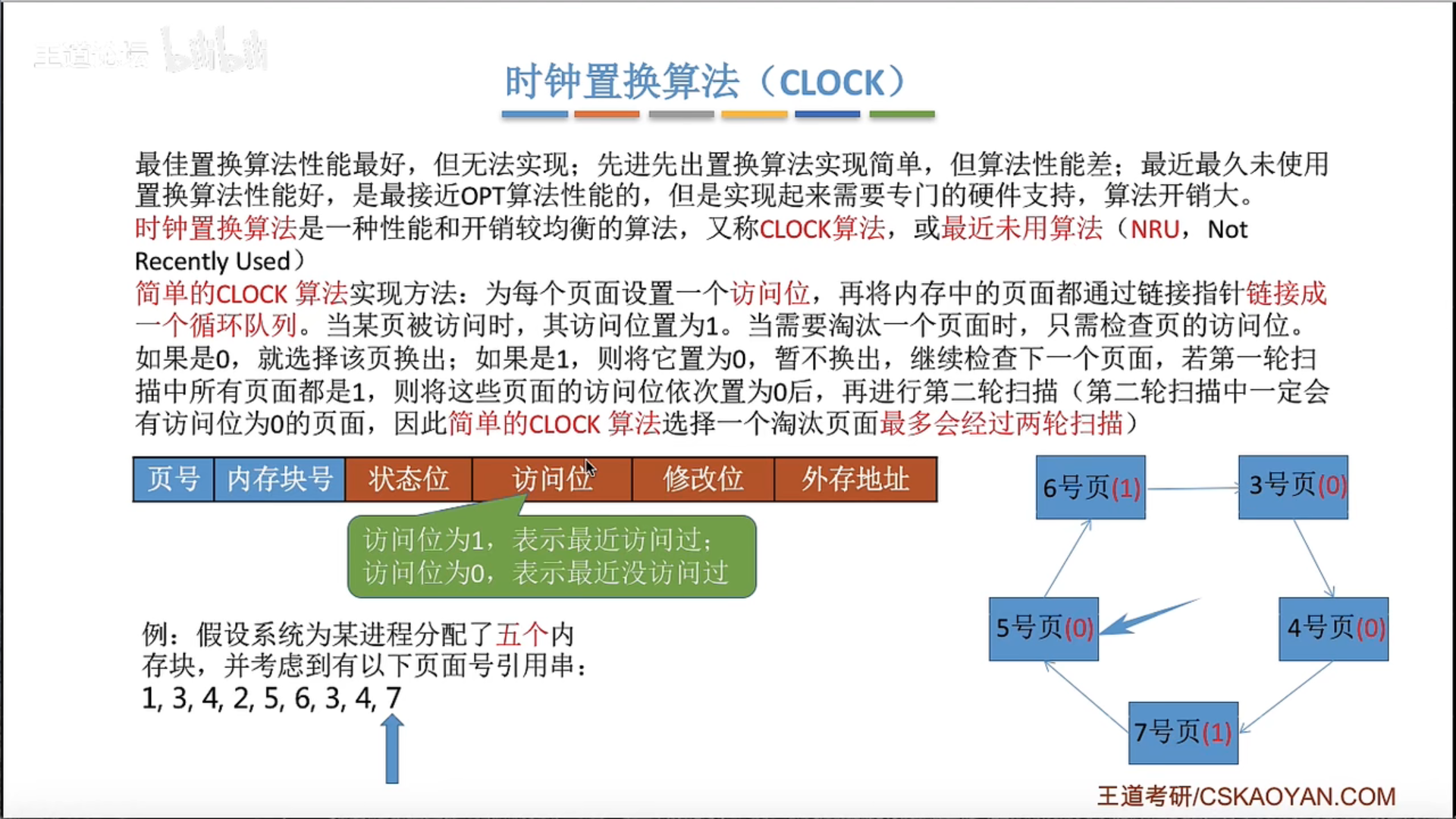
也就是说只有发生缺页的时候,才需要进行扫描,没有发生缺页的时候,直接把访问位置1就可以了
是的,你的理解是正确的。
在正常的内存访问过程中,如果一个页面已经在物理内存中(即,没有发生缺页),那么在访问这个页面的时候,只需要把这个页面的引用位设置为1,表示这个页面最近被访问过。这个过程不需要进行扫描。
只有当发生缺页错误,也就是说需要访问的页面不在物理内存中时,才需要进行页面替换。此时,时钟置换算法会启动扫描过程,找到一个合适的页面进行替换。这个过程需要根据时钟指针的位置,依次检查每个页面的引用位,直到找到一个引用位为0的页面。找到后,这个被选中的页面会被替换掉,新的页面会被加载到内存中,同时更新时钟指针的位置。


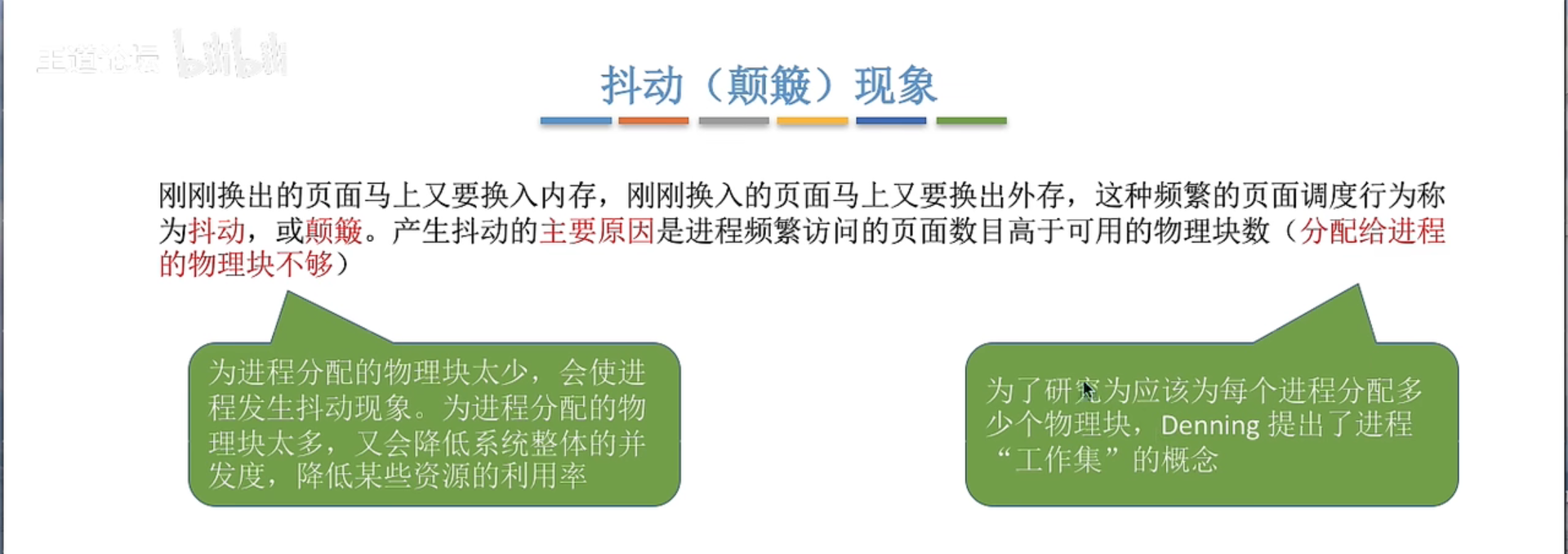
3.2.3 页框分配 3.2.5 抖动和工作集





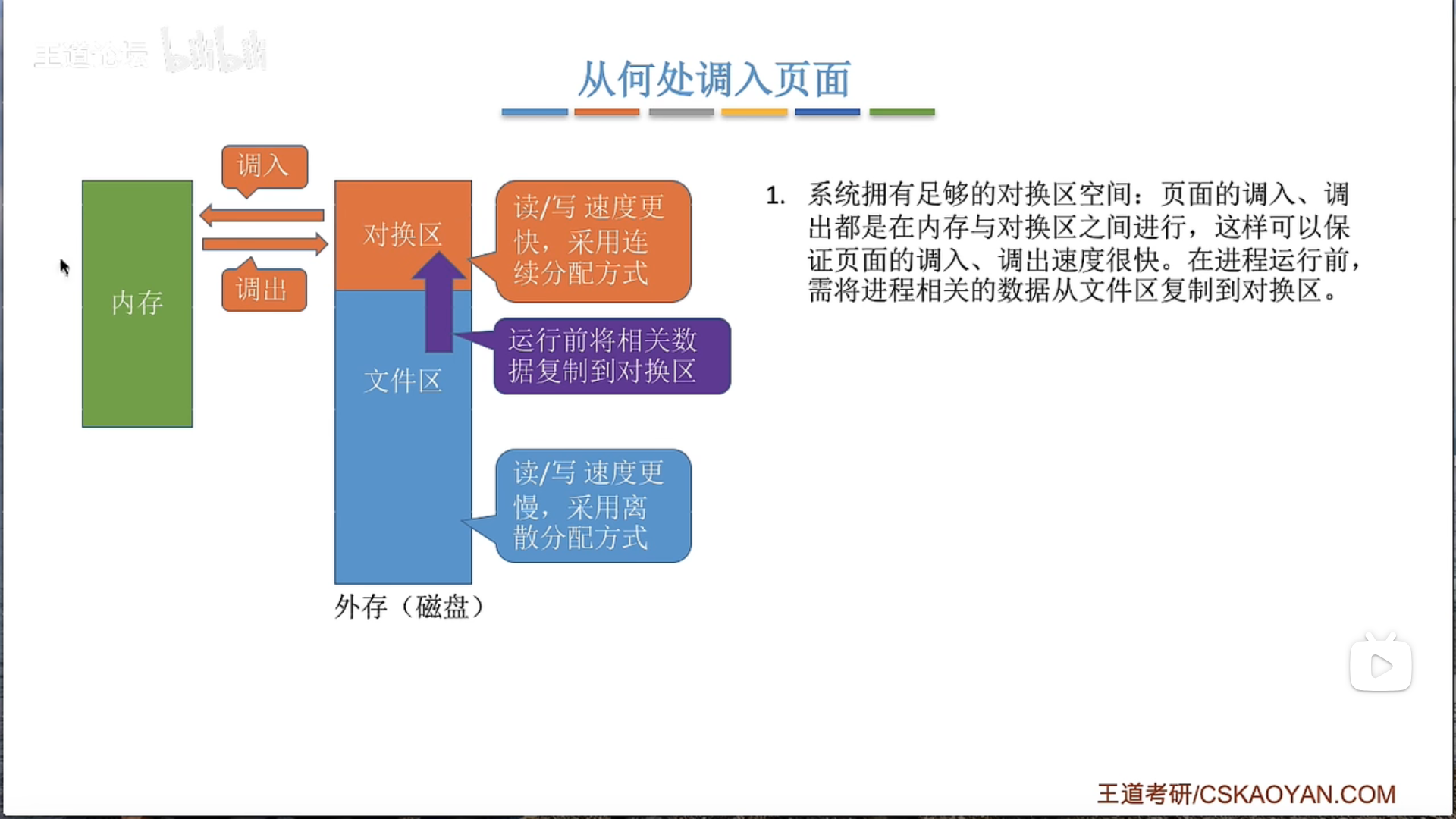

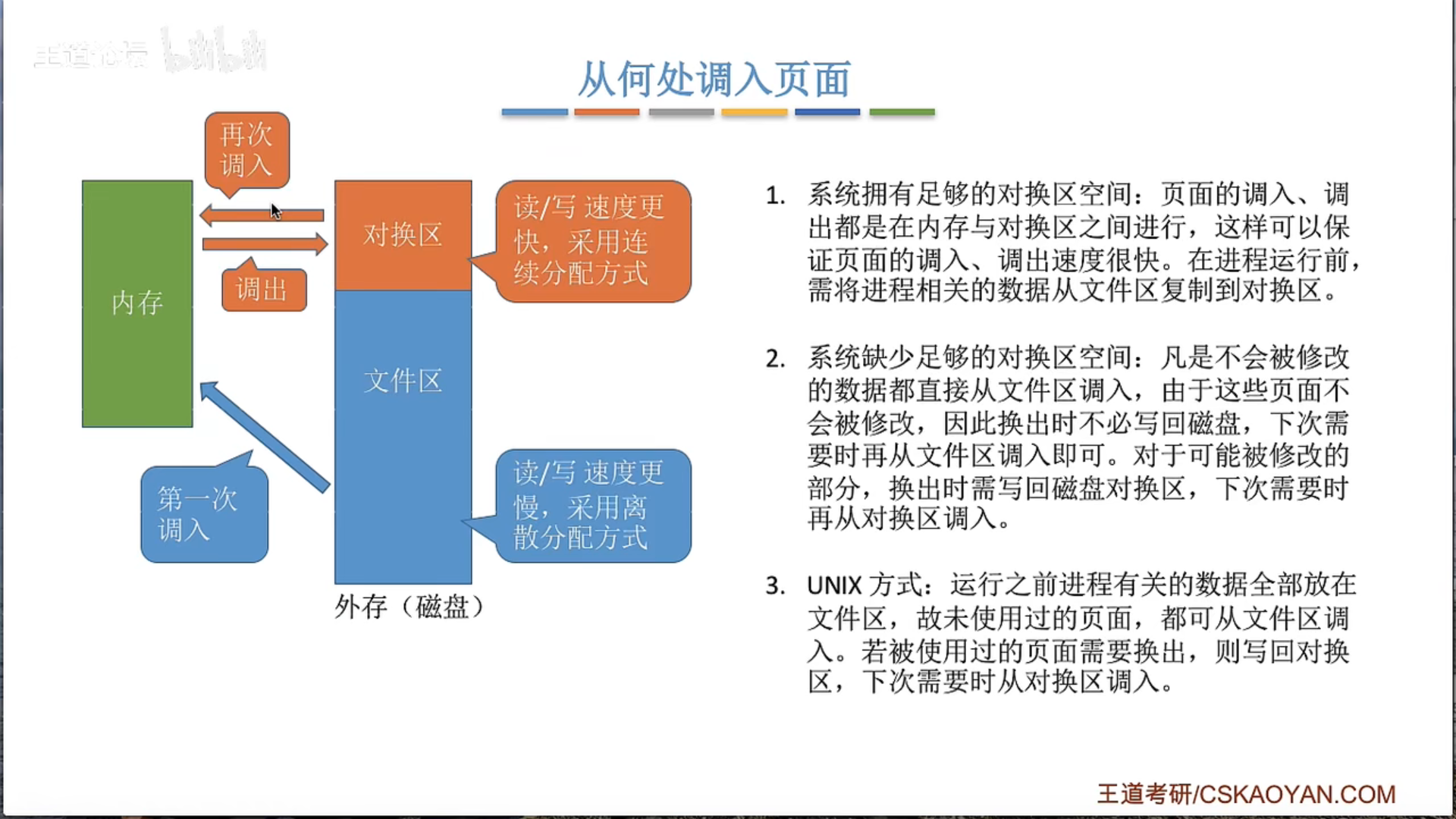
抖动颠簸
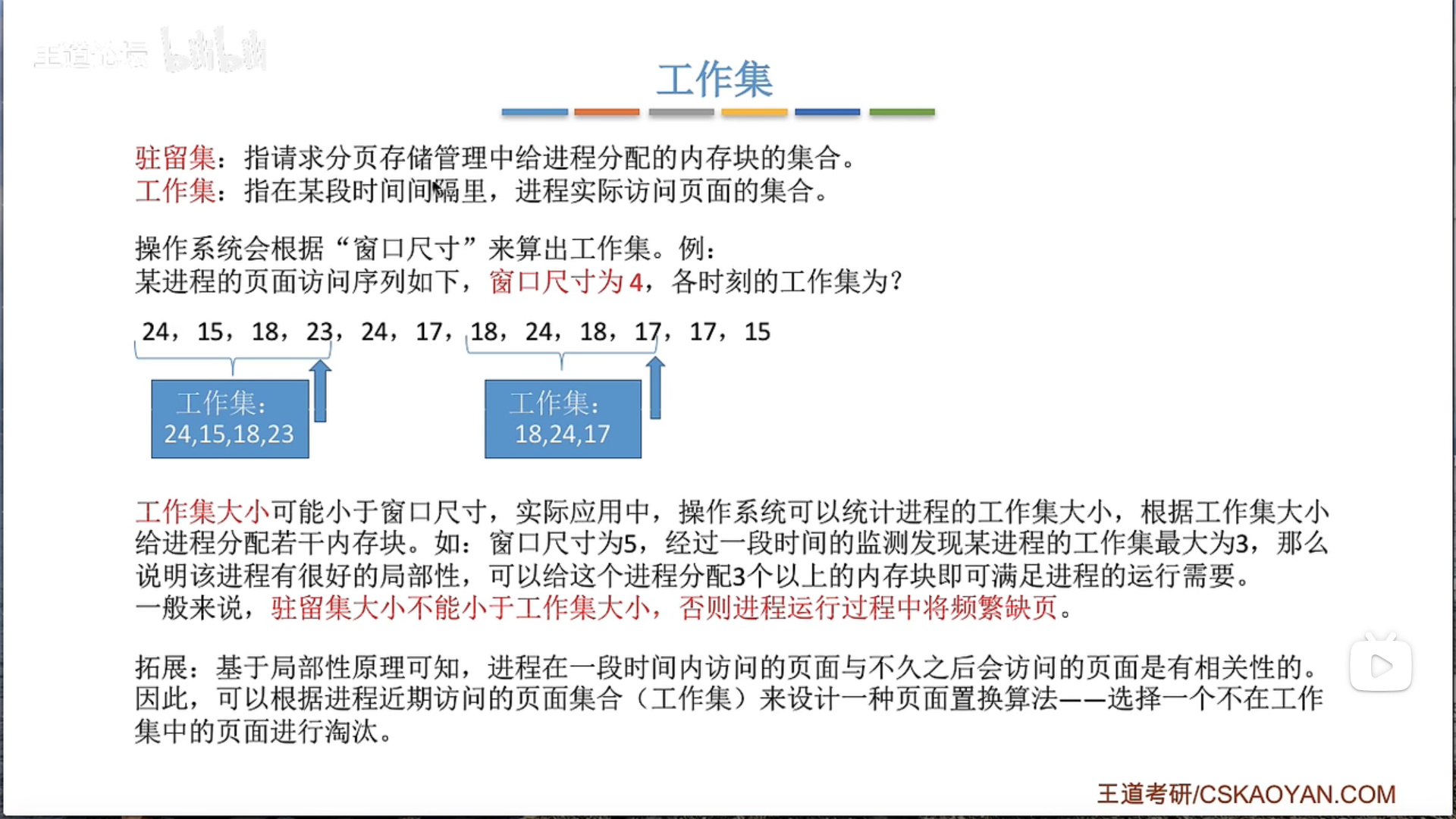
3.2.6 内存映射文件

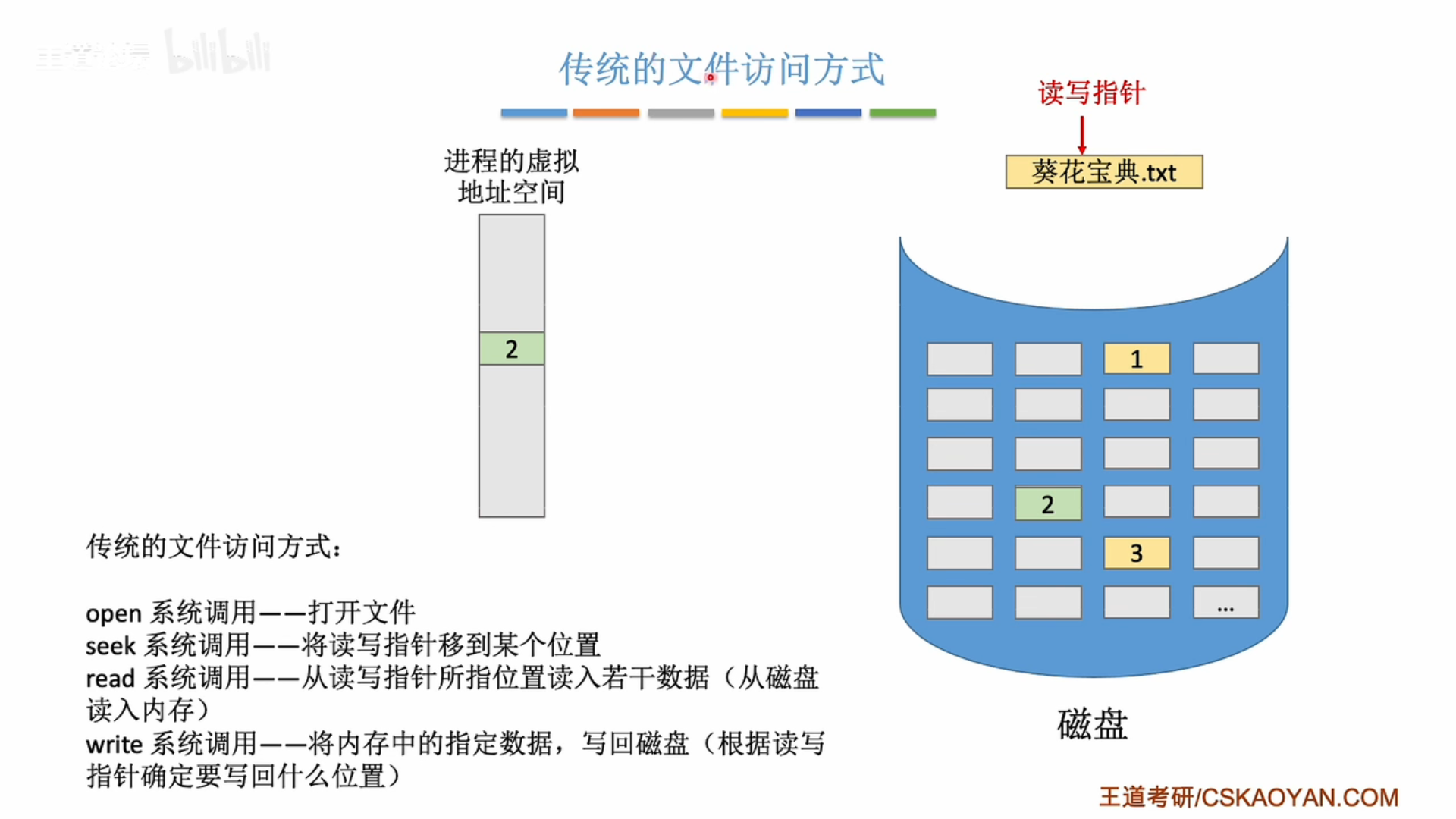
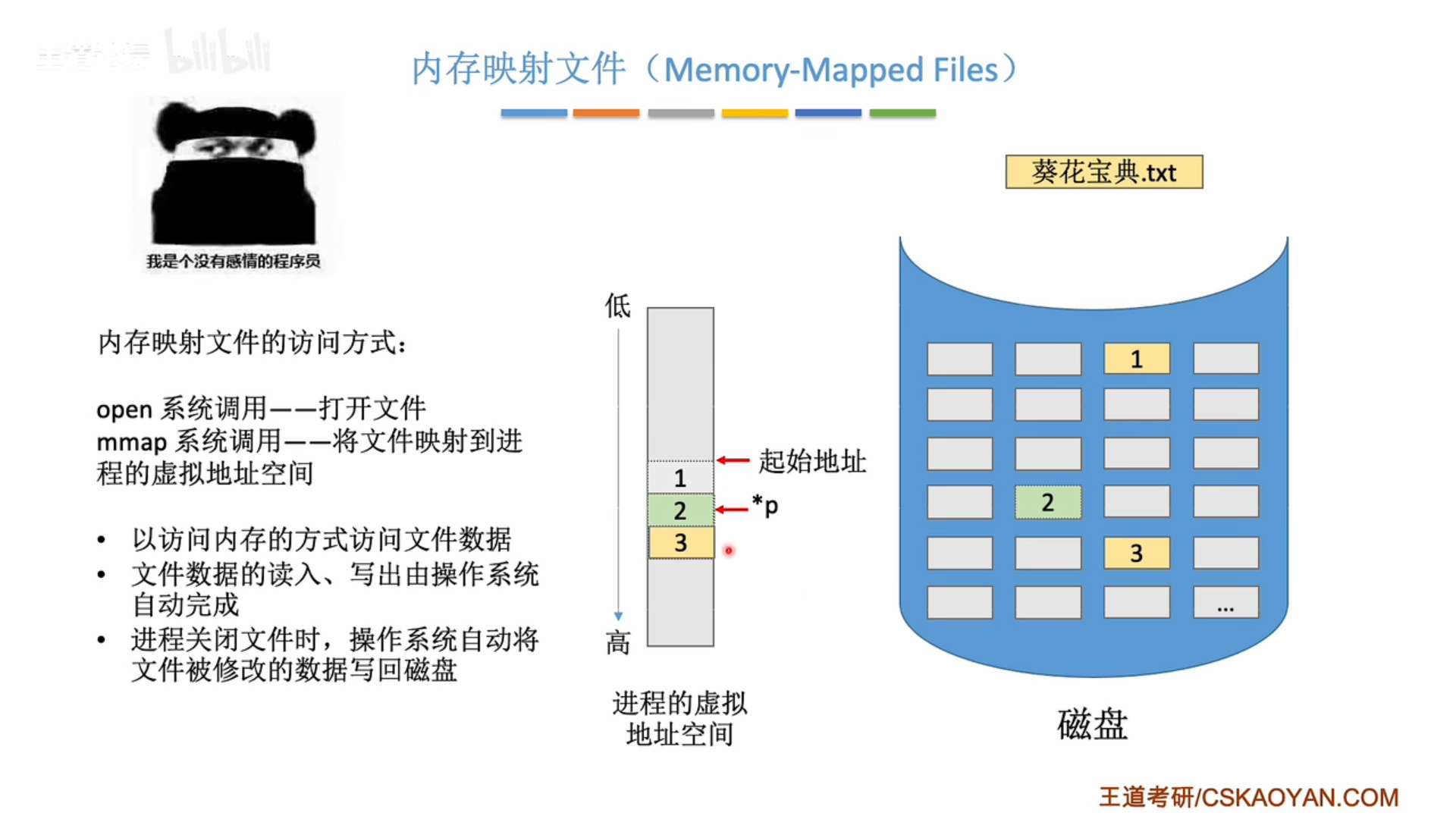
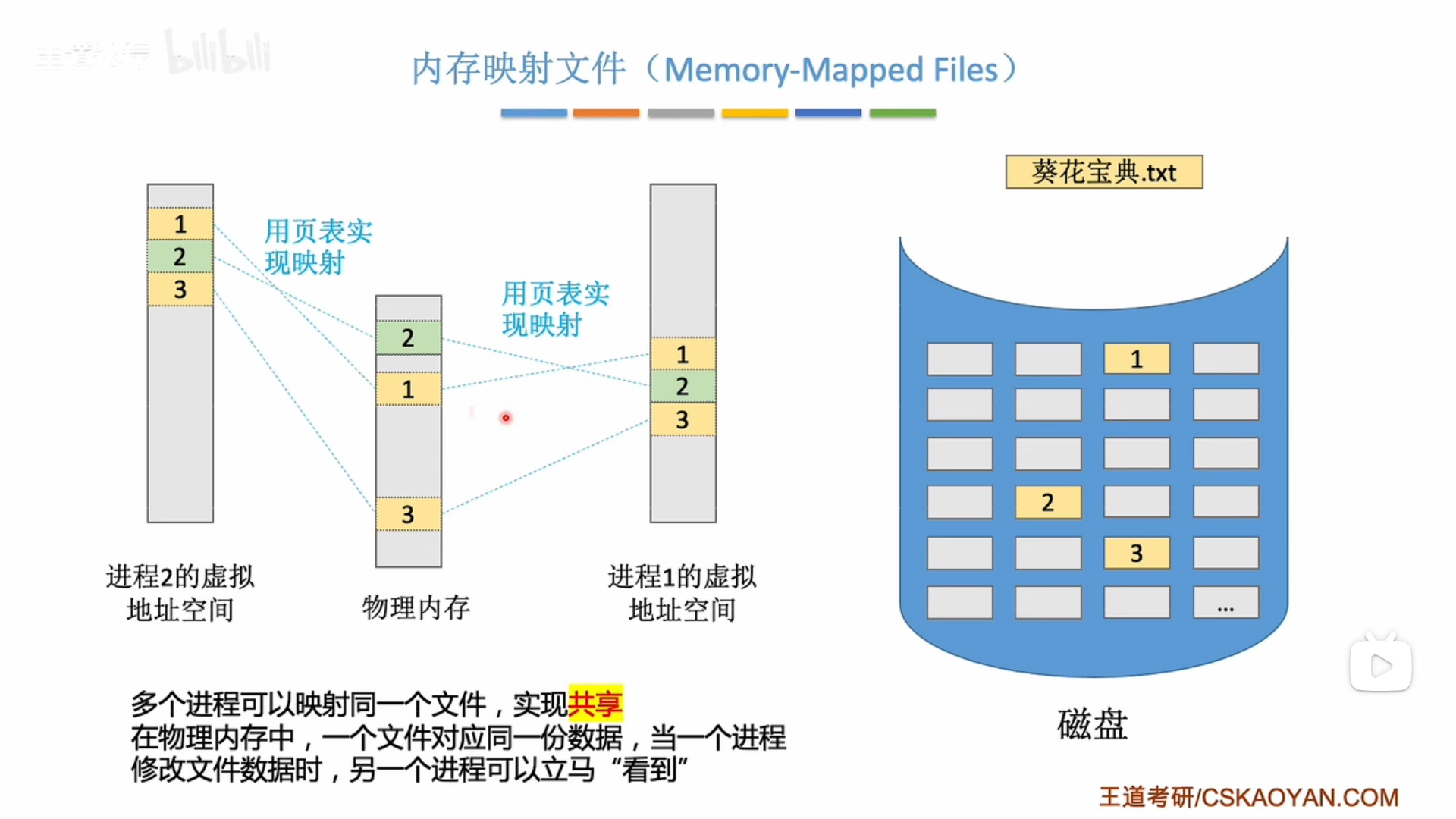
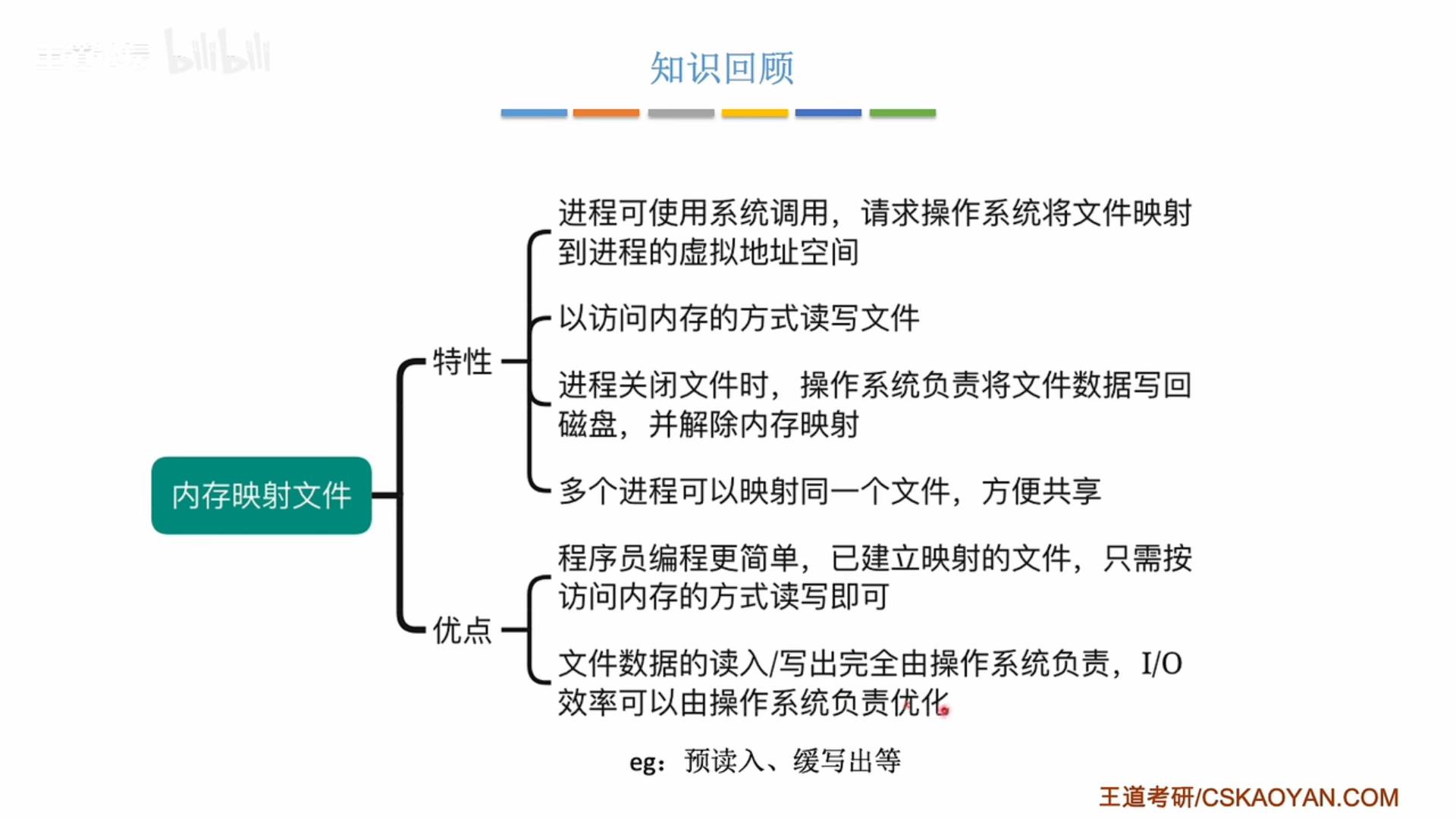
mmap() 是一个用于在内存中映射文件的函数,它是Unix和类Unix系统(如Linux)提供的一种方法,允许程序将一个文件或者其它对象映射进内存,对文件进行操作就像直接操作内存一样。
其基本的函数原型是:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);参数解释:
-
addr: 希望得到的映射区的起始地址,通常设为NULL,让内核来选择映射区的起始地址。 -
length: 要映射的文件的长度。 -
prot: 设置内存区域的保护方式,可取值为PROT_EXEC、PROT_READ、PROT_WRITE、PROT_NONE。 -
flags: 指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个MAP_SHARED、MAP_PRIVATE、MAP_TYPE、MAP_FIXED、MAP_ANONYMOUS、MAP_GROWSDOWN等的组合。 -
fd: 文件描述符,需要映射的文件。 -
offset: 文件的偏移量,通常设为0,表示从文件最开始处进行映射。
mmap()成功的话返回映射区的内存起始地址,失败的话返回 MAP_FAILED (void *)-1。
使用 mmap() 对文件进行内存映射后,就可以直接操作内存进行读写,而不必调用 read()、write() 等系统函数。这样可以消除这些函数调用的开销,提高效率。但是这样也直接暴露了内存,需要自己处理好边界和同步等问题。
当你使用mmap()函数将文件映射到内存后,操作系统会返回一个指向该内存区域的指针。这个内存区域的内容就是你映射的文件的内容。你可以像操作数组或者其他内存区域一样直接读取或写入这个指针指向的内存。简单来说,你就可以把这个内存区域当做是一个大的字符数组,用这个指针来索引你要访问的内容。
例如,以下是一段使用mmap()读取文件内容的C语言代码:
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <stdio.h>
int main() {
int fd = open("test.txt", O_RDONLY);
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("fstat");
return 1;
}
char *p = mmap(0, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
if (p == MAP_FAILED) {
perror("mmap");
return 1;
}
for (int i = 0; i < sb.st_size; i++) {
putchar(p[i]);
}
return 0;
}在这个例子中,我们使用mmap()函数将文件test.txt映射到内存,然后使用一个循环和putchar()函数将文件的内容打印出来。注意这里我们是直接通过索引内存指针p来访问文件内容的,没有使用read()或者write()函数。
注意:在使用完mmap()后,你应该使用munmap()函数来释放这个内存区域,防止内存泄漏。
Comments NOTHING